Ovo je možda najveća HOT tematika na planeti u poslednje vreme, pa otvaram temu o tome izjavom Elona Muska, čoveka koji je, složićemo se, veoma upućen u te prilike:
Elonu je samo mnogo krivo sto je izasao iz OpenAI-ja i sto je najveci dobitnik cele te price ispao Microsoft a ne on... mislim, ironicno je da on prica o bojazni od AI a sam je medju prvima ubacio AI u voznju automobila. Takodje, Tesla je jedan od najvecih kupaca AI hardvera za treniranje svojih algoritama za autonomnu voznju.
Da je dobio ono sto je trazio u OpenAI-ju (mesto CEO-a) i ostao sa svojim investicijama, danas bi pricao sasvim drugu pricu.
Ovo je jedna od stvari gde se zaje*ao, ali to je skroz OK - svako je samo covek, pa makar i vrlo pametan i uspesan covek kao Elon.
Inace, to sto ce se desiti je zapravo vec 'gotovo' u smislu, trajektorija postoji i nista je nece spreciti - cak i da razvoj AI algoritama odjednom stane sutra, ono sto je vec moguce sa state-of-the-art modelima je dovoljno dobro da solidno umanji posao 'sljakerskih' poslova. Gomila tih poslova ce biti zamenjena AI/ML algoritmima i to se vec desava, bas kao sto su PC racunari sa spreadsheet softverom zamenili gomilu manuelnog rada u npr. racunovodstvu i sl.
To nece dovesti do nekakvog kraja sveta, ali ce za odredjenu generaciju ljudi znaciti dodatno obucavanje i promenu posla, bas kao sto se isto to desavalo nebrojeno puta ranije.
[ Nebojsa Milanovic @ 27.05.2024. 18:59 ] @
Apsolutno se slažem da u njegovim "opštim" izjavama o Ai ima i lične komponente, nadovezaću se ovom informacijom:
[ djoka_l @ 27.05.2024. 21:20 ] @
Microsoft planira da uloži u AI još 110 milijardi dolara. Mislim da je to plan za sledeće 4 godine (ili 5).
Google je najavio za sledeću godinu 4-5 miljardi dolara.
Mask je opasan ludak i neće ništa da uradi. Samo je dobar u prikupljanju novca, ništa realizacija.
Microsoft će da popravi značajno GPT.
Google če kaskati.
Meta je praktično ispala iz trke.
Za 5 godina, Mask će biti u zatvoru. Kada se sruši njegova piramidalna šema.
[ dejanet @ 27.05.2024. 22:04 ] @
Silikon i nuklearke da to sve tera.
To je ono sto sada nedostaje.
[ Nebojsa Milanovic @ 28.05.2024. 00:15 ] @
@Ivan, a i ostali
Evo pojašnjenje Muskovog opusa i Tesle - sa i bez Ai
(autor je ozbiljan analitičar, pratim ga 10+ godina)
[ djoka_l @ 28.05.2024. 07:23 ] @
OK, ajde da vidimo Maskov opus.
Oterali su ga iz PayPala, ali je dobio dobru cenu.
Pravi prilično dobre i preskupe električne automobile. Napravio oko 5 miliona komada
Napravio je totalno sr*nje sa Cybertrackom, do sada prodao 4000 i svi si vraćeni na ispravku bagova. Najavio je da će da košta 40k, košta 90k. Neće moći da ih izvozi u EU, u stvari bilo gde van USA, zbog toga što nisu bezbedni ni za pešake, ni za vozače.
Od 2017. godine prima uplate za kamione. Pravi ih poslednje dve godine, i do sada ih je napravio manje od 100
Od 2017. godine prima uplate za roadster (novu verziju), do sada nije isporučio ni jedan.
Hyperloop, mrtav.
Boring kompanija mrtva.
SpaceX, do sada je trebalo da pošalje ljude na Mesec i Mars, stigao je jednom do niske orbite, ali se raketa srušila. Pre toga eksplodirala i oštetila lansirni blok. Falscon rakete, po njegovom planu, su trebale da imaju mogućnost da se lansiraju u razmaku manjem od 3 dana, ali retko upe da lansira jednom mesečno.
Robot, smejurija.
Autonomna vožnja - ne radi.
Sve u svemu, jedino što mu je do sada stvarno uspelo, to su neki modeli EV, ali ga opasno ugrožava BYD, ali i drugi (afirmisani) proizvođači automobila.
[ scoolptor @ 28.05.2024. 07:58 ] @
Elon je 2019. predvideo da ce do kraja 2020. Tesla imati milion robo-taxi vozila na ulicama USA.
Evo, 2024. je, a jos uvek nista...
Poslednje obecanje je da ce 8. avgusta 2024. biti lansiran Tesla robo-taxi. Videcemo...
Dok druge kompanije, kao sto su Waymo i Cruise, imaju funkcionalna robo-taxi vozila na ulicama pojedinih americkih gradova.
U Kini takodje imamo vise kompanija koje imaju svoja robo-taxi vozila na ulicama.
Teslin FSD softver je jos uvek level 2, dok neke kompanije imaju level 4 FSD sisteme na ulicama.
Teslin potencijal je ogronma kolicina podataka koje prikupljaju senzorima na vozilima svojih musterija - i situaciju na putu i reakcije vozaca,
koje mogu da koriste za razvoj svog FSD sistema.
Pre neki dan sam gledao intervju sa Elonom. Novinar pominje da je Elon zapravo Toni Stark iz stvarnog zivota. Elon je uzvratio zadovoljnim osmehom.
Mene licno Elon vise podseca na Lajla Lenlija iz Simpsonovih.
Elem, ceo balon sa AI proizveo je GPT, ili da budem precizniji, veliki jezički modeli (LLM).
Bez obzira a to što su ponekad rezultati LLM impresivni, totalno je pogrešno u celu priču ubacivati robote i autonomnu vožnju.
Roboti postoje odavno, rade uveliko u mnogim insustrijskim granama, ali neki univerzalni humanoidni robot je daleko od bilo kakvog rešenja.
Roboti koji hodaju na dve noge još uvek imaju problem sa ravnotežom, kretanjem po neravnom terenu itd.
Autonomna vozila i dalje nisu autonomna.
Potpuino suludo je zamišljati da će neko postrojenje kao što je GPT u De Mojnu da se skalira na dole, tako da stane u automobil. Verovatno ne bi stalo ni u voz ili u tanker.
Isto važi i za robote. Nema teorije da ChatGPT vozi kola ili pokreće robota, a minijaturizacija cele infrastrukture na nivo ljudske veličine je još uvek naučna fantastika.
Čisto za poređenje, najavljuju da če potrošnja struje sledeće verzije ChatGPT biti na nivou potrošnje struje Njujorka. Da ne govorim o bazenima vode za hlađenje pstrojenja.
[ Ivan Dimkovic @ 28.05.2024. 11:13 ] @
Datacentre mozes da gradis i na okeanu, tu ima vode koliko hoces :-)
Odakle ideja da GPT (tj. LLM) algoritmi treba da voze kola? Zasto bi? Algoritmi za L3 autonomnu voznju staju sasvim lagano u SoC-eve iz 2024, dok 2028 ce SoC-evi sa >2000 TOPS-ova moci da trce sve sto se planira za L4+.
Sama problematika uopste ne zahteva jezicki model, vec je poprilicno poznata i razradjena i sastoji se iz percepcije (computer vision, sensor fusion), rezonovanja i planiranja rute i upravljanja vozilom. LLM nicemu tu ne doprinosi vec su to sve ograniceni problemi za koje resenja vec postoje, daleko su vece prepreke zakonodavne prirode i, mozda najvaznije, pitanja odgovornosti (tj. ko placa stetu kada/ako se desi).
Robotaksiji vec saobracaju u vise gradova, logicno je da se to ne radi naglo vec u etapama ali, na kraju krajeva, neminovno je da ce pre ili kasnije da se desi u sirokoj upotrebi.
[ djoka_l @ 28.05.2024. 11:38 ] @
Većina robotaxi službi ne funkcioniše autonomno.
Skoro sve što radi, ili ima vozače za volanom ili iza kompjutera u dispečerskom centru.
Tamo gde funkcionišu, u nekoj meri autonomno, ne funkcionišu u celom gradu, nego u samo nekim delovima, a funkcionišu tako što svakog dana prolaze vozila sa kamerama da bi DNEVNO osvežavali algoritme, jer je sistem autonomne vožnje još uvek dovoljno glupav, da ne može da se osloni na kamere, radare i GPS.
LLM sam samo pomenuo u kontekstu IA balona. Činjenica je da LLM radi drugačiju stvar nego sistem za autonomnu vožnju, ali se neopravdano uspesi LLM prikazuju kao generalni pomaci i u drugim AI sistemima, koji nemaju veze sa LLM.
Ili primer Maska, koji tvrdi da Tesla ima autonomnu vožnju (a nema), pa da na osnovu toga ima gotov AI model za humanoidnog robota, što nema veze jedno sa drugim, osim "nalepnice" AI.
Dodatak, Tesla ima L2, šta god Mask tvrdio. Ne postoji ni jedan sistem sa L5
[ Ivan Dimkovic @ 28.05.2024. 14:42 ] @
Citat:
djoka_l
jer je sistem autonomne vožnje još uvek dovoljno glupav, da ne može da se osloni na kamere, radare i GPS.
Mozes gledati na stvari tako, a opet - mozes gledati i ovako: pre samo 10 godina je sve to bilo cista naucna fantastika. Waymo, npr, nema backup vozaca jos od 2019.
Sa druge strane, polako su poceli u upotrebu da ulaze L3 sistemi za putnicka vozila (Mercedes Benz Drive Pilot) - sa ogranicenjima, naravno, tipa samo auto put, odredjen opseg brzina i vreme u toku dana, ali sve to nikako i ne bi smelo drugacije da se razvija, ipak su u pitanju gomile ljudskih zivota i celoj stvari se pristupa sa najvise moguce opreza. Ali napreduje.
--
Tacno, sve to nije ni izbliza rapidno kao sto su neki procenjivali da ce da se desi 2015-te - ali, desava se i uzevsi u obzir o koliko kriticnom aspektu zivota se tice, bolje je sto ide ovim tempom a ne tempom nekog SV startupa sa standardnim dolinskim motom "move fast and break things"... to u ovom slucaju definitivno nije dobra ideja.
Sto se uspeha LLM-a tice i pripisivanja toga drugim stvarima, mislim da je stvar samo parcijalno istinita.
Tacno je da se cesto LLM napredak koristi, greskom, kao 'proksi' za druge grane AI/ML, pre svega zato sto je LLM revolucija nesto jako blizu onoga sto su ljudi ranije smatrali ekskluzivnim domenom ljudskog razmisljanja.
Ali netacan deo je sledeci: pre transformer revolucije ('Attention is all you need' rad - https://arxiv.org/abs/1706.03762), doslo je do dramaticnog napredka i u drugim granama AI/ML, pre svega vezano za Computer Vision domen - ne bih propustao enormni skok u mogucnostima racunara da identifikuju i klasifikuju objekte, kao ni mogucnosti da generisu sadrzaj (GAN i srodni algoritmi). Transformeri su samo poslednje u nizu inovacija koje se, prakticno, konstantno desavaju od ranih 2010-tih.
[ djoka_l @ 28.05.2024. 15:39 ] @
Malo se ne slažem sa tvojom hronologijom.
Ako pogledaš
DARPA Grand Challenge 2004
DARPA Grand Challenge 2005
videćeš da 2004. nijedan automobil/robot nije uspeo da dođe do cilja, dok su 2005. godine skoro svi stigli na cilj.
Dakle autonomna vožnja je u razvoju poslednjih 20 godina (intenzivno).
Doduše, ta dva takmičenja su bila u pustinji, nema pešaka, nema drugog saobraćaja, svejedno i tada je bilo teško savladati 200km autonomno, pa se rešavalo.
Rad koji se pominje u videu dostupan je na arxiv, a u samom radu su dati linkovi za github repozitorijum sa kodom, kao i link do dataset-a: https://arxiv.org/abs/2404.04125
Da li je ono što autori u navedenom radu zaključuju tačno, videćemo, ali činjenica jeste da će za neku sledeću verziju ChatGPT-a biti potrebno mnogo više podataka, a za to je neophodno eksponencijalno više hardvera, što drastično povećava troškove, pa je pitanje do koje granice će ulaganja u sve to imati smisla. Da ne bude kao sa trkom u osvajanju Meseca, pa posle pauza duža od pola veka.
Kad se razvoj AI i konkretnije velikih jezičkih modela (LLM) uporedi sa nekim drugim istorijskim probojima u tehnologiji i industriji, naveo bih primer projektovanja objektiva za fotoaparate u eri pre računara - proračuni su rađeni ručno od strane velikog broja ljudi koji su testirali različite kombinacije uglova pod kojim svetlo pada na svako od sočiva ili tako nešto (human calculators).
Slična priča je za ručno razbijanje šifara pre ere računara. Da li su svi ti ljudi, koji su zbog računara ostali bez takvih poslova, završili na ulici? Nisu, čak se može reći da sada recimo jedan Canon, Nikon, Fuji ili Sony čak zapošljava više ljudi u svojim foto/video sektorima.
Slično je za AI, samo postoji jedna mala razlika: IT kompanije su u poslednjih nekoliko decenija nicale kao pečurke posle kiše, mnoge rasle eksponencijalno po profitu i broju uzaposlenih, ali se došlo do nekog zasićenja, tako da nema ni blizu takvog rasta kao pre 20 godina, plus velike kompanije su promenile pristup - radije kupuju uspešne startapove nego da zapošljavaju hiljade programera na projektima koji verovatno neće uspeti. Zbog toga je u zadnjih 10 ili nešto više godina globalno zabeležen ogroman rast startapova, ali sada je i tu dostignuto neko zasićenje (Srbija tu malo kasni, pa nam se čini da ima još prostora za značajan rast), tako da za nove "ajtijevce" nema mnogo prostora čak i da ne postoje ChatGPT i slični alati (ima mnogo boljih AI alata za specifične zadatke, ali to je neka druga tema).
[ Ivan Dimkovic @ 28.05.2024. 17:55 ] @
Citat:
djoka_l:
Malo se ne slažem sa tvojom hronologijom.
Ako pogledaš
DARPA Grand Challenge 2004
DARPA Grand Challenge 2005
videćeš da 2004. nijedan automobil/robot nije uspeo da dođe do cilja, dok su 2005. godine skoro svi stigli na cilj.
Dakle autonomna vožnja je u razvoju poslednjih 20 godina (intenzivno).
Doduše, ta dva takmičenja su bila u pustinji, nema pešaka, nema drugog saobraćaja, svejedno i tada je bilo teško savladati 200km autonomno, pa se rešavalo.
Ja bih kao relevantniju meru uzeo broj kilometara/milja predjenih od strane autonomih algoritama na >otvorenim putevima<
Sa par stotina hiljada km neke 2014-2015 se stiglo do ~70 miliona km. u 2023, samo u USA.
To je u normalnom saobracaju, ne na poligonima u pustinjama.
Dosta je to polje uznapredovalo, sto zbog samih algoritama a sto zbog mogucnosti hardvera. Primera radi, dolazeci NVIDIA Thor ce imati 2000 TOPS mogucnost procesiranja, sto je do pre samo 15-tak godina bio iskljucivo domen superracunara. A i sami algoritmi su dosta uznapredovali, pogotovu klasifikacija i detekcija objekata.
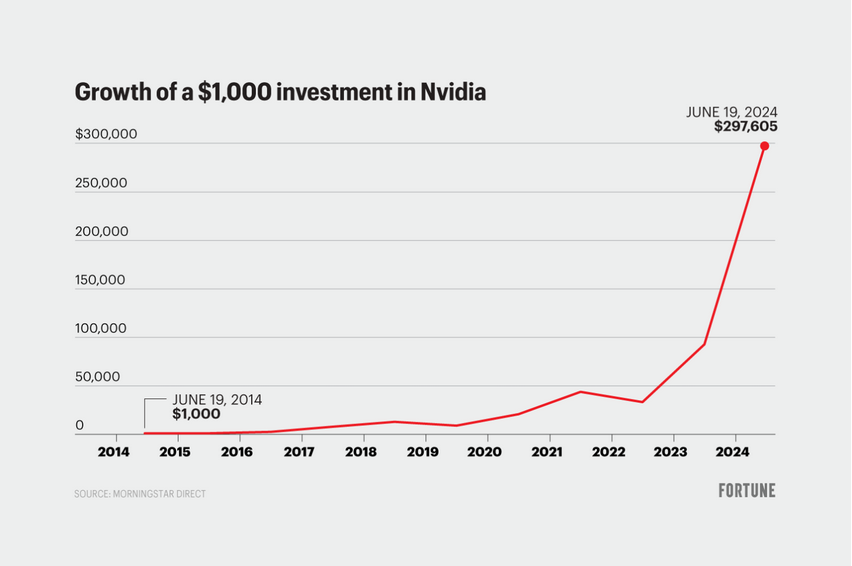
[ Nebojsa Milanovic @ 28.05.2024. 22:01 ] @
Kad si spomenuo NVIDIA:
+272,5%
Ovo je stanje akcije samo u poslednjih godinu dana, a ako se pogleda duži tajm-frejm situacija je još puno drastičnija.
Samo to već dovoljno govori da prisustvujemo blago rečeno revoluciji, kao možda nikada do sada.
[ Ivan Dimkovic @ 29.05.2024. 08:50 ] @
Nvidia je jedna od najimpresivnijih kompanija - to sto su oni izveli je bukvalno za knjige.
Inace, koga zanima - istorija osnivanja i ranog poslovanja je tek ludilo:
Nvidia was founded on April 5, 1993,[26][27][28] by Jensen Huang (CEO as of 2024), a Taiwanese-American electrical engineer who was previously the director of CoreWare at LSI Logic and a microprocessor designer at AMD; Chris Malachowsky, an engineer who worked at Sun Microsystems; and Curtis Priem, who was previously a senior staff engineer and graphics chip designer at IBM and Sun Microsystems.[29][30] The three men founded the company in a meeting at a Denny's roadside diner in East San Jose.[31][32]
Citat:
Nvidia initially had no name and the co-founders named all their files NV, as in "next version".[33] The need to incorporate the company prompted the co-founders to review all words with those two letters.[33] At one point, Malachowsky and Priem wanted to call the company NVision, but that name was already taken by a manufacturer of toilet paper.[32] Huang suggested the name Nvidia,[32] from "invidia", the Latin word for "envy".[33] The company's original headquarters office was in Sunnyvale, California.[33]
Citat:
Nvidia also signed a contract with Sega to build the graphics chip for the Dreamcast video game console and worked on the project for a year.[36] Having bet on the wrong technology, Nvidia was confronted with a painful dilemma: keep working on its inferior chip for the Dreamcast even though it was already too far behind the competition, or stop working and run out of money right away.[36]
Eventually, Sega's president at the time, Shoichiro Irimajiri, came to visit Huang in person to deliver the news that Sega was going with another graphics chip vendor for the Dreamcast.[36] However, Irimajiri still believed in Huang, and "wanted to make Nvidia successful".[36] Despite Nvidia's disappointing failure to deliver on its contract, Irimajiri somehow managed to convince Sega management to invest $5 million into Nvidia.[36] Years later, Huang explained that this was all the money Nvidia had left at the time, and that Irimajiri's "understanding and generosity gave us six months to live".[36]
In 1996, Huang laid off more than half of Nvidia's employees—then around 100—and focused the company's remaining resources on developing a graphics accelerator product optimized for processing triangle primitives: the RIVA 128.[32][35]
By the time the RIVA 128 was released in August 1997, Nvidia was down to about 40 employees[31] and only had enough money left for about one month of payroll.[32]
The sense of extreme desperation around Nvidia during this difficult era of its early history gave rise to "the unofficial company motto": "Our company is thirty days from going out of business".[32] Huang routinely began presentations to Nvidia staff with those words for many years.[32]
[ Ivan Dimkovic @ 29.05.2024. 08:59 ] @
Inace, ja sam bio ponosni vlasnik RIVA-e 128 davne 1998-me... pola odeljenja je bilo parkirano kod mene da picimo igrice, toliko je taj akcelerator bio ispred vremena.
Kad prvi put vidis bilinearno (valjda?) filtrirane teksture sa nekoliko desetina FPS... bilo je bukvalno kao magija.
[ dr0id @ 29.05.2024. 12:31 ] @
Citat:
Ivan Dimkovic:
Datacentre mozes da gradis i na okeanu, tu ima vode koliko hoces :-)
Odakle ideja da GPT (tj. LLM) algoritmi treba da voze kola? Zasto bi? Algoritmi za L3 autonomnu voznju staju sasvim lagano u SoC-eve iz 2024, dok 2028 ce SoC-evi sa >2000 TOPS-ova moci da trce sve sto se planira za L4+.
Sama problematika uopste ne zahteva jezicki model, vec je poprilicno poznata i razradjena i sastoji se iz percepcije (computer vision, sensor fusion), rezonovanja i planiranja rute i upravljanja vozilom. LLM nicemu tu ne doprinosi vec su to sve ograniceni problemi za koje resenja vec postoje, daleko su vece prepreke zakonodavne prirode i, mozda najvaznije, pitanja odgovornosti (tj. ko placa stetu kada/ako se desi).
Robotaksiji vec saobracaju u vise gradova, logicno je da se to ne radi naglo vec u etapama ali, na kraju krajeva, neminovno je da ce pre ili kasnije da se desi u sirokoj upotrebi.
Ja mislim da algoritmi za L5 mogu sasvim lagano da trce na SoC-evima iz 2014. ako se ne komplikuje previse vec koriste istrenirani modeli i najosnovnije prepoznavanje i planiranje rute, umesto sto komplikuju do besvesti, kreiraju 3D grafiku okruzenja i trose resurse na gluposti.
Citat:
Ivan Dimkovic:Ja bih kao relevantniju meru uzeo broj kilometara/milja predjenih od strane autonomih algoritama na >otvorenim putevima<
Sa par stotina hiljada km neke 2014-2015 se stiglo do ~70 miliona km. u 2023, samo u USA.
To je u normalnom saobracaju, ne na poligonima u pustinjama.
Dosta je to polje uznapredovalo, sto zbog samih algoritama a sto zbog mogucnosti hardvera. Primera radi, dolazeci NVIDIA Thor ce imati 2000 TOPS mogucnost procesiranja, sto je do pre samo 15-tak godina bio iskljucivo domen superracunara. A i sami algoritmi su dosta uznapredovali, pogotovu klasifikacija i detekcija objekata.
I ovo isto, par stotina (ma i desetina) hiljada km ucenja na profi vozacima je bolje od 70 miliona km ucenja na onima koji uglavnom ne znaju da voze, imaju spore i neadekvatne reakcije i sl.
[ Nebojsa Milanovic @ 30.05.2024. 16:12 ] @
Za NVDA se vezuje više neverovatnih fenomena, meni je najzanimljivija profitabilnost poslednjih nekoliko kvartala.
To je apsolutno neviđeno u industriji, a da ne pričam tako naglo i pri tolikom market-kapu.
Inače NVIDA kao firma već u ovom trenutku je veća OD CELOKUPNE industrije Nemačke, a biće samo još veća naravno.
[ sikira069 @ 01.06.2024. 19:06 ] @
Nvidia kao firma veća od cele Nemačke industrije?
Mercedes, BMW, Audi, WV, Siemens, Bayer...
Ne verujem da veća i od nekih od ovih firmi pojedinačno.
Amerikanci hiljadu miliona (1.000.000.000) ne zovu milijarda, kao u Evropi, već bilion.
Tako da njihove cifre treba deliti sa 1.000 ili Nemačke množiti sa 1.000 kada se porede firme.
[ MajorFatal @ 01.06.2024. 20:03 ] @
Ako ugradiš nvidia karticu u bmw možeš da mu dupliraš vrednost ..
[ Ivan Dimkovic @ 01.06.2024. 22:14 ] @
Citat:
Ne verujem da veća i od nekih od ovih firmi pojedinačno.
Sta tu ima da se veruje?
Nvidia moze da kupi ne nemacku nego celu globalnu auto industriju bez da zajmę pare od bańkę.
[ Nebojsa Milanovic @ 01.06.2024. 22:29 ] @
Dve stvari su gore od trola:
1) Nepismeni trol
2) Bezobrazni trol
A kada u jednom trolu imate to objedinjeno zajedno, za sada ne postoji naziv za to
[ MajorFatal @ 01.06.2024. 23:21 ] @
Citat:
Ivan Dimkovic:
Sta tu ima da se veruje?
Nvidia moze da kupi ne nemacku nego celu globalnu auto industriju bez da zajmę pare od bańkę.
Nvidia moze da kupi ne nemacku nego celu globalnu auto industriju bez da zajmę pare od bańkę.
Pa što ne kupe?
Sto bi kupili biznis koji je N puta manje profitabilan od njihovog? Koji ce im? Da umanji njihovu vrednost?!
[ djoka_l @ 02.06.2024. 18:57 ] @
Uh, ala sam lupio, odnekuda mi iskočilo 75%
Međutim, ima tu još interesntnih podataka.
NVIDIA isplaćuje oko 11 dolara dividende po akciji, što mu dođe oko 1% od trenutne cene akcije.
DAX ima oko 3% (u proseku) prinosa na akcije.
NVIDIA u ovom momentu ima profit oko 30 milijardi dolara, što ispadne da za 100 godina pokriva svoju tržišnu kapiralizaciju.
Ruku na srce, profit joj je enorman, ide na oko 50-60 procenata od prodaje, što je fantastično.
Sa druge strane, treba joj 50 godina da proda onoliko koliko joj je tržaišna kapitalizacija.
Ovako visok proft je zato što NVIDIA ima niske troškove, njene čipove pravi TMSC.
[ MajorFatal @ 02.06.2024. 19:05 ] @
Citat:
Ivan Dimkovic:
Sto bi kupili biznis koji je N puta manje profitabilan od njihovog? Koji ce im? Da umanji njihovu vrednost?!
Paa.. da. A i da imaju čime da se voze kad idu negde. U kom smislu n puta manje profitabilan, i na koji način da umanje vrednost?
[ Nebojsa Milanovic @ 02.06.2024. 19:21 ] @
Citat:
djoka_l:
Koliko u besmisleni podaci o tržišnoj kapitalizaciji neke firme vidimo na osnovu sledećih podataka:
Tržišna kapitalizacija ARM je 126 milijardi dolara
Tržišna kapitalizacija NVIDIA je 2.7 biliona dolara (2700 milijardi dolara)
ARM ima u svom vlasništvu udeo u NVIDIA firmi od 75%
ARM ima u svom vlasništvo akcije NVIDIA "vredne" 2100 milijardi dolara.
ARM na tržištu vredi 17 puta manje nego što vredi njegovo učešće u NVIDIA.
Ne znam odakle si prepisao ove nebuloze (možeš da pokažeš), ali u moru bizarnih i manje bizarnih budalaština koje ovde vidimo, hajda da probamo da ne gubimo fokus.
Na prošloj sam rekao par važnih stvari, između ostalog da je market cap NVIDIA veći od celokupne nemačke industrije, i okačio najnoviji grafik:
Rekoh za NVIDIA se vezuje više neverovatnih fenomena, meni je najzanimljivija profitabilnost poslednjih nekoliko kvartala. To je apsolutno neviđeno u industriji, a da ne pričam tako naglo i pri tolikom market-kapu.
Ali glavna poenta je što cena akcija NVIDIA u ovom trenutku na marketu uopšte nije velika imajući u vidu prikazane parametre, tačnije market cap NVIDIA bi trebao biti JOŠ VEĆI, ako gledate bukvalno svaki ili bilo koji ekonomski kriterijum.
Mada je i ovako kao što vidimo enorman, on nije još veći SAMO ZATO što investitori ne veruju da će potražnja prema NIVIDA čipovima biti onakva kakvu je uprava najavila na earnings call-u.
U narednim kvartalima će se videti ko je bio u pravu: da li uprava sa svojim projekcijama, da li optimisti (koji sada kupuju NVDA akcije) - ili pesimisti koji su bili skeptični prema tolikom daljem rastu.
O NVIDIA će se svakako knjige pisati (i već se pišu verujem), jer od kada postoji industrija do sada nikada se nije desilo da na tolikom marketcapu neka firma ima toliku profitabilnost.
Može se uporediti sa Amazonom recimo, čiji je mcap tu-negde. On je (napamet pričam, mrzi me da tražim) najmanje 10 puta manje profitabilan od NIVIA, što je normalno.
[ jovajovic100 @ 03.06.2024. 08:43 ] @
Citat:
sikira069: Inače Nvidia je neverovatan uspon doživela zbog rudarenja kriptovaluta. Prodavali su grafičke čipove po 3 do 10 puta većoj ceni od regularne. Klasično zelenašenje.
Čim rudarenje ide dole i Nvidia ide dole.
Marcet cap onda pada mnogo brže od rasta.
NVIDIA se tako ugojila zbog rata u u Ukrajini , a ne zbog kripto valuta .
U ozbiljnim dronovima su njihove ploče . Kažu da se u nekim dronovima
koji prave ršum po Ukrajini nalaze Jetson TX2 Module Nvidia .
I Microsoft i Apple imaju veću tržišnu kapitalizaciju od Nvidia .
[ Ivan Dimkovic @ 03.06.2024. 09:00 ] @
NVIDIA se ugojila zbog AI trzista, njihov glavni proizvod su A100/H100/B100 akceleratori, koji sada kostaju nekoliko desetina hiljada dolara po komadu, sa vremenom cekanja od preko godinu dana. Bukvalno se najveci kupci biju da stanu u red i kupuju na hiljade.
Kriptovalute su bile samo privremeni peak, koji nije bio orkestriran od strane NVIDIA-e nego su se oni samo zatekli tu i iskoristili situaciju prodajom oskrnavljenih kartica kao CMPxxx modela. Inace ko je citao kvartalne izvestaje tada, seca se da su taj efekat u NVIDIA-i tretirali kao poslovni rizik zbog nepredvidljivosti tog trzista. Drugim recima, to je bio momenat van poslovne strategije koji je samo dobro iskoriscen.
AI je sasvim druga prica, NVIDIA je jedna od firmi koje su, zapravo, omogucili AI bum, da ne pricamo o tome da je CUDA de-facto standard za HPC/naucne aplikacije koje zahtevaju jak compute. To je strateski najvazniji segment u toj firmi, a cifre to pokazuju:
Citat:
In fiscal 2024, NVIDIA's revenue from its Graphics business segment reached $13.517 billion, while revenue from its Compute & Networking segment amounted to nearly $47.4 billion.May 23, 2024
Ukratko, compute segment donosi >3.5x vise novca od grafike danas i NVIDIA je radila godinama na tome da to postane tako.
Citat:
MajorFatal
Paa.. da. A i da imaju čime da se voze kad idu negde. U kom smislu n puta manje profitabilan, i na koji način da umanje vrednost?
U smislu da od $X prodaje NVIDIA-i ostaje $Y zarade, gde je odnos $X/$Y nekoliko puta veci od odnosa $X/$Y u auto industriji.
$X/$Y je profitna margina, i predstavlja faktor koji ulazi u kalkulisanje isplativosti akcija. Taj faktor pokazuje koliko je isplativ neki biznis.
Najprostije receno, na svaki dolar prodaje, NVIDIA zaradi 4.33x vise love od VW-a.
Firma sa visokim profitnim marginama nece kupovati firme sa mnogo manjim profitnim marginama (osim iz nekih strateskih razloga, tipa manje profitabilna firma poseduje neku kljucnu tehnologiju ili komponentu koja je strateski bitna za biznis prve firme i kupovina predstavlja najbolji scenario) zato sto bi time skoro pa automatski umanjili vrednost svojih akcija.
@djoka_l,
Gleamo, dakle, PE odnos (Price to Earnings) - koji je trenutno 63.4, taj faktor je zapravo implicitno ocekivanje trzista da ce vrednost NVIDIA akcija da raste u buducnosti, sto je i ocekivano uzevsi u obzir stanje AI industrije.
Te stvari mogu lako da se promene preko noci, ali u ovom momentu vrednost NVIDIA akcija je sasvim na mestu.
[ MajorFatal @ 03.06.2024. 19:32 ] @
Citat:
sikira069:
Nedostaje samo tačan podatak o marcet capu celokupne Nemačke industrije.
Paa .. sabere sve marcet capove svih firmi i to je to, uključujući Nemicu što pravi kore za gibanice.
Pretpostavljam da negde mora da se uglavi da nemačka industrija zapošljava manje više sve Nemce, a da nVidia zapošljava na primer .. 55.000 zaposlenih .. od toga 10 inžinjera koji razvijaju novu karticu, i 55.990 marketing stručnjaka koji duvaju marcet cap?
Citat:
sikira069:
Čim rudarenje ide dole i Nvidia ide dole.
Marcet cap onda pada mnogo brže od rasta.
Onda je još malo mnogo gore, onda marcet cap mora da jarca i propada kao da neko jaše divljeg bika, jer postoji armija onih koji kupuju dok je "deep" a prodaju kad je "high" i od toga zarađuju i žive. nVidiji se isplati da isplati tih 150 x 10^6 $ ako će oni da fingiraju da je vrednost firme 10^9 ...
Citat:
Ivan Dimkovic:
U smislu da od $X prodaje NVIDIA-i ostaje $Y zarade, gde je odnos $X/$Y nekoliko puta veci od odnosa $X/$Y u auto industriji.
$X/$Y je profitna margina, i predstavlja faktor koji ulazi u kalkulisanje isplativosti akcija. Taj faktor pokazuje koliko je isplativ neki biznis.
Najprostije receno, na svaki dolar prodaje, NVIDIA zaradi 4.33x vise love od VW-a.
Firma sa visokim profitnim marginama nece kupovati firme sa mnogo manjim profitnim marginama (osim iz nekih strateskih razloga, tipa manje profitabilna firma poseduje neku kljucnu tehnologiju ili komponentu koja je strateski bitna za biznis prve firme i kupovina predstavlja najbolji scenario) zato sto bi time skoro pa automatski umanjili vrednost svojih akcija.
Da li je mnogo nelogično pitanje zašto ekipa VW lepo ne proda aute, fabrike, akcije i deonice, i sve uloži u nVidia? Zvuči tupavo baviti se srednje žalosnim profit biznisom, kad ti je pred nosem bogovski nVidia profitabilni biznis, samo uložiš ..
[ Nebojsa Milanovic @ 03.06.2024. 20:55 ] @
Citat:
NVIDIA se tako ugojila zbog rata u u Ukrajini
Ne znam otkud ti ovo, nešto od čipova se svakako koristi u ratu na obe strane (pokazivo sam delove sa AMD procesorima), ali sve je to totalno zanemarljivo u odnosu na data-centre.
Data-centri su daleeeko najveći potrošač NVIDIA čipova, sa godišnjim rastom na nivou 400-500%.
Evo nekoliko dijagrama sa kojih je sve očigledno:
[ djoka_l @ 04.06.2024. 09:32 ] @
Ja sam izračunao market cap DAX (40 firmi ulazi z DAX) i on je 1.8 biliona.
Koliki je ukupan market cap SVIH firmi koje se kotiraju na berzi u Frankfurtu, nije mi poznato.
Berza u Frankfurtu je najveća u Nemačkoj, a mislim da imaju 7 berzi. Sve ostale su znatno manje.
Neko tvrdi da je ukupan market cap svih nemačkih firmi 2.5 biliona, što je možda tačno, ako je neko potrošio vreme da ih sve sabere.
Samo da pojasnim Majoru, market cap se računa samo za one firme koje se kotiraju na berzi, a ne i za domaćice koje razvlače kore kod kuće.
[ anakin14 @ 05.06.2024. 16:20 ] @
Citat:
djoka_l:
Microsoft planira da uloži u AI još 110 milijardi dolara. Mislim da je to plan za sledeće 4 godine (ili 5).
Google je najavio za sledeću godinu 4-5 miljardi dolara.
Mask je opasan ludak i neće ništa da uradi. Samo je dobar u prikupljanju novca, ništa realizacija.
Microsoft će da popravi značajno GPT.
Google če kaskati.
Meta je praktično ispala iz trke.
Za 5 godina, Mask će biti u zatvoru. Kada se sruši njegova piramidalna šema.
Daj leba ti kazi nam i ko ce osvojiti Evropsko prvenstvo ove godine kad vec sve znas...
Koje budalastine...
[ MajorFatal @ 08.06.2024. 14:11 ] @
Citat:
sikira069:
Ko kupi akcije NVIDIA je ozbiljan kockar.
Čim Kinezi priđu Tajvanu, akcije idu na 0.
To ti je "deep" tad kupuješ, posle kad porastu i opet krenu da padaju prodaješ, i tako zarađuješ na razlici, problem je u tome što i svi drugi tako rade, inače .. u vezi sa Tajvanom:
Niko: - ništa, lep dan danas možda
bbCnn1: - Gomila internet kablova ispod Tajvana, "ako" Kina zarati može da ih razbuca ?? 23 miliona ljudi bez interneta, elon musk je uložio dosta u starlink ali nije dovoljno, bla, bla
Citat:
djoka_l:
Samo da pojasnim Majoru, market cap se računa samo za one firme koje se kotiraju na berzi, a ne i za domaćice koje razvlače kore kod kuće.
To im je velika greška, jer šta će da jede radnik u Mercedesu kad uveče dođe kući .. biću iskren, naravno da ne znam šta je "market cap" zamišljam ga kao neki ekonomski berzanski parametar koji se računa kao uzmi, smuti, prospi, pomnoži, podeli, dodaj lepe želje i eto .. jer bi inače bilo nvidia ima toliko na računu, bmw ima toliko, i onda ovi kupe ove ili obrnuto.
[ djoka_l @ 08.06.2024. 14:41 ] @
Market Cap (market capitalization) ili tržišna kapitalizacija je "vrednost" kompanije na berzi. Jednostavno to je broj akcija puta vrednost akcije. Nikakva složena matemtaika, proizvod dva broja.
[ MajorFatal @ 08.06.2024. 15:06 ] @
Paa.. nikakva složena matematika za nekog ko zna brojeve i matematiku, ali za mene šta znam, već mi sumnjivo na prvom koraku, u pitanju je "broj akcija" onda nije isto ako firma izda 1000 akcija, i ako objavi 100.000 akcija i ako akcije prve vrede 1000$ a ove druge 1$, ispada da ima je market cap isti, ali meni ne deluje da su to iste ili slične firme ..
Svejedno da bi kupili celu nečiju auto industriju morali bi prvo da prodaju akcije, da bi uzeli lovu sa kojom da kupe, ali onda mora da postoji neko sa lovom, a da nema njihove akcije, i po mogućstvu da nije vlasnik auto industrije, da bi kupio od njih, pa tek onda da kupuju akcije auto industrije, ali onda nisu vlasnici ni svog biznisa, sve u svemu komplikovano, a nit ovi kupuju njihove, nit ovi njihove, pa smatram da to ne ide tako lako, nego samo na papiru.
[ djoka_l @ 08.06.2024. 23:05 ] @
Nema veze po kojoj ceni su akcije nekada u prošlosti prodate.
Akcije su "sličice".
Firma je emitovala milion sličica. Cena na berzi za svaku sličicu je 2 (na primer) po današnjem stanju berze.
Market cap je 1,000,000 * 2 = 2 miliona novčanih jedinica.
Sutra je cena na berzi 3, onda je sutra market cap 3 miliona.
[ MajorFatal @ 09.06.2024. 22:07 ] @
Dobro, ali zašto ta ista firma nije umesto milion emitovala 1000 sličica, sa cenom na berzi po 2000 svaka opet bi market cap bio 2 miliona novčanih jedinica, a sutra cena na berzi 3000 onda sutra market cap 3 miliona, sve isto .. ali bi mogli da se hvale među drugim firmama: Vidi ova naša jedna akcija 3000$ a vidi one tamo bednike akcija im 3$, a u stvari market cap im isti, isto vrede.
[ Ivan Dimkovic @ 10.06.2024. 08:08 ] @
Monetarna (trenutna) vrednost akcije je besmislen podatak bez ukupnog broja akcija (sto ti daje market cap) i fundamentalnih parametara poslovanja firme.
Mozes ti da emitujes koliko hoces akcija ali vrednost tvoje firme utvrdjuje trziste na osnovu pomenutih fundamentalnih parametara i prognoza kuda idu trziste i tvoja firma u njemu, pa bi se na bilo koju vrednost i broj akcija brojevi nivelisali na ocekivanje trzista u odnosu na realnost. Samu vrednost akcija odredjujes ne ti kao emiter, vec samo oni koji akcije kupuju i prodaju.
TL;DR - vredis koliko su drugi spremni da plate.
Kao firma, emitovanjem svojih akcija bez da se ista promeni umanjujes njihovu vrednost, dok kupovinom svojih akcija bez da se ista drugo menja im povecavas vrednost (neke firme to rade - vidi 'stock buyback', to je nesto sto je nekim firmama u USA strategija umesto isplate dividendi zato sto je poreski trenutno efikasnija).
[ djoka_l @ 10.06.2024. 11:58 ] @
Citat:
MajorFatal:
Dobro, ali zašto ta ista firma nije umesto milion emitovala 1000 sličica, sa cenom na berzi po 2000 svaka opet bi market cap bio 2 miliona novčanih jedinica, a sutra cena na berzi 3000 onda sutra market cap 3 miliona, sve isto .. ali bi mogli da se hvale među drugim firmama: Vidi ova naša jedna akcija 3000$ a vidi one tamo bednike akcija im 3$, a u stvari market cap im isti, isto vrede.
Zašto postavljaš besmislena pitanja?
Da li je veći baja onaj milioner koji ima milion novčanica od 1 dolar ili onaj koji ima 10 hiljada od 100 dolara?
Cena akcije je potpuno nebitna, osim kao faktor koji se koristi da se pomnoži sa brojem akcija.
Osim toga, inicijalnu cenu pojedinačne akcije određuje firma koja izlazi na berzu, kasnije kretanje cene akcije diktira ponuda i potražnja na berzi.
Inicijalna cena je "vrednost apoena". Ima puno razloga da inicijalna cena bude mala, recimo 10 ili 100 jedinica.
Ako si ti mali akcionar i kupuješ akcije kao vid štednje, možda nemaš 1000 dolara da kupiš akciju od 1000 dolara, nego si uštedeo 500 dolara, pa možeš da kupiš 50 akcija koje pojedinačno vrede po 10 dolara.
Za velike investitore je potpuno nebitno koliko košta pojedinačna akcija, ali je za male bitno.
[ Ivan Dimkovic @ 10.06.2024. 13:50 ] @
Obicno firme cija vrednost akcija naraste puno urade 'split' tj. za svakih X akcija emituju jos Y, kako bi cena pojedinacne akcije ponovo postala OK za male investitore - sto djoka_l rece, za one koji kupuju akcije kao vid stednje, za velike investitore je nebitno koliko jedinica akcija vredi, ono sto je bitno je da li fundamentalni parametri firme jesu u saglasnosti sa investicionom strategijom.
NVIDIA je upravo uradila 10:1 split i jedna akcija od $1208.88 je postala 10 akcija od $120.88 - sustinski se nista nije promenilo, svako ko je imao N akcija NVIDIA-e sada ima 10*N akcija. Vrednost firme je ostala ista.
Berza je samo nacin da se brze dodje do razmene izmedju ljudi koji poseduju kapital i ljudi koji poseduju udeo u vlasnistvu firme. Sto se same vrednosti firme tice, fundamentalno nista nije razlicito izmedju firmi van berze i firmi koje se trguju na berzi. "Market cap" tj. trzisna vrednost firme na berzi zavisi od istih faktora od kojih zavisi i vrednost firme koja nije na berzi, jedino je lakse doci do vlasnistva dela firme koja je na berzi, zato sto je to moguce svakom ko ima novca i ko ima pristup trading platformama.
[ sikira069 @ 10.06.2024. 14:09 ] @
I sutra će akcije otići + ili -.
Klasična kocka.
Berza uzima istu proviziju akcionarima kao i Mozzart kladionica igračima.
Ne vidim razliku.
Ovamo se kladiš na Nvidiu, a u Mozzartu na Real.
[ djoka_l @ 10.06.2024. 14:34 ] @
Ne vidiš razliku?
Možeš da kupiš plac, a država uzme proviziju (porez). A cena placa može da ode + ili -
Da li je to isto kao kladionica?
Ili ni tu ne vidiš razliku?
[ sikira069 @ 10.06.2024. 16:34 ] @
Za plac vidim razliku. Kupuje se da bi napravio kuću i tu živeo. Neophodnost.
Berza je kockanje.
Zarađuju samo organizatori.
[ Ivan Dimkovic @ 10.06.2024. 17:54 ] @
Kockarima je sve kocka i logicno je da ne vide razliku posto im je mozak nabazdaren da u svemu vide nacin da ispolje sopstvene defekte.
Hint: vecina vlasnika akcija se ne kockaju sa njima vec zaradjuju ili na dividendama ili na rastu akcija na duzi rok.
Citat:
Za plac vidim razliku. Kupuje se da bi napravio kuću i tu živeo. Neophodnost.
Najveci vlasnici akcija su penzioni fondovi kao i uzajamni fondovi u kojima ljudi parkiraju lovu i stite je od inflacije. Niko se tu ne kocka vec je berza jedan od stubova njihovih investicionih strategija i trivijalno je videti da najvise zaradjuju upravo oni sto je potpuno suprotno od tvrdnje da "zaradjuju samo brokeri". Parkirati deo slobodne love na 5-10-15 godina u blue-chip akcije na berzi je pametna stvar i nema nikakve veze sa kockom vec je zdrav razum.
Kockari od svega naprave kocku, akcije su samo jedan od bezbroj nacina da ispoljavaju svoju zavisnost. Da, na njima najvise zaradjuju brokeri - sto ne bi, dok je curana bice i podvarka.
[ sikira069 @ 10.06.2024. 18:24 ] @
Jedino sigurno je dati u Poštansku štedionicu na skoro 3% godišnje kamate koliko je bilo u martu na devizne uloge.
Ne verujem da te blue-chip akcije stalno rastu.
Nekada i padaju. To chip je baš pokeraški izraz.
[ Nebojsa Milanovic @ 10.06.2024. 18:41 ] @
Citat:
sikira069:Ne verujem da te blue-chip akcije stalno rastu.
Niko nije rekao da akcije stalno rastu.
Često i padaju, i to veoma jako, imali smo prilike samo u poslednjih par godina da to vidimo XXX puta.
No, osim što pričaš isto kao većina totalno neobrazovanih ljudi i predstavljaš najgore od njih, prosečan Srbin, iako često glup, nije tako pokvaren kao ti, da toliko uporno da ruši svaku smislenu diskusiju na ES-u.
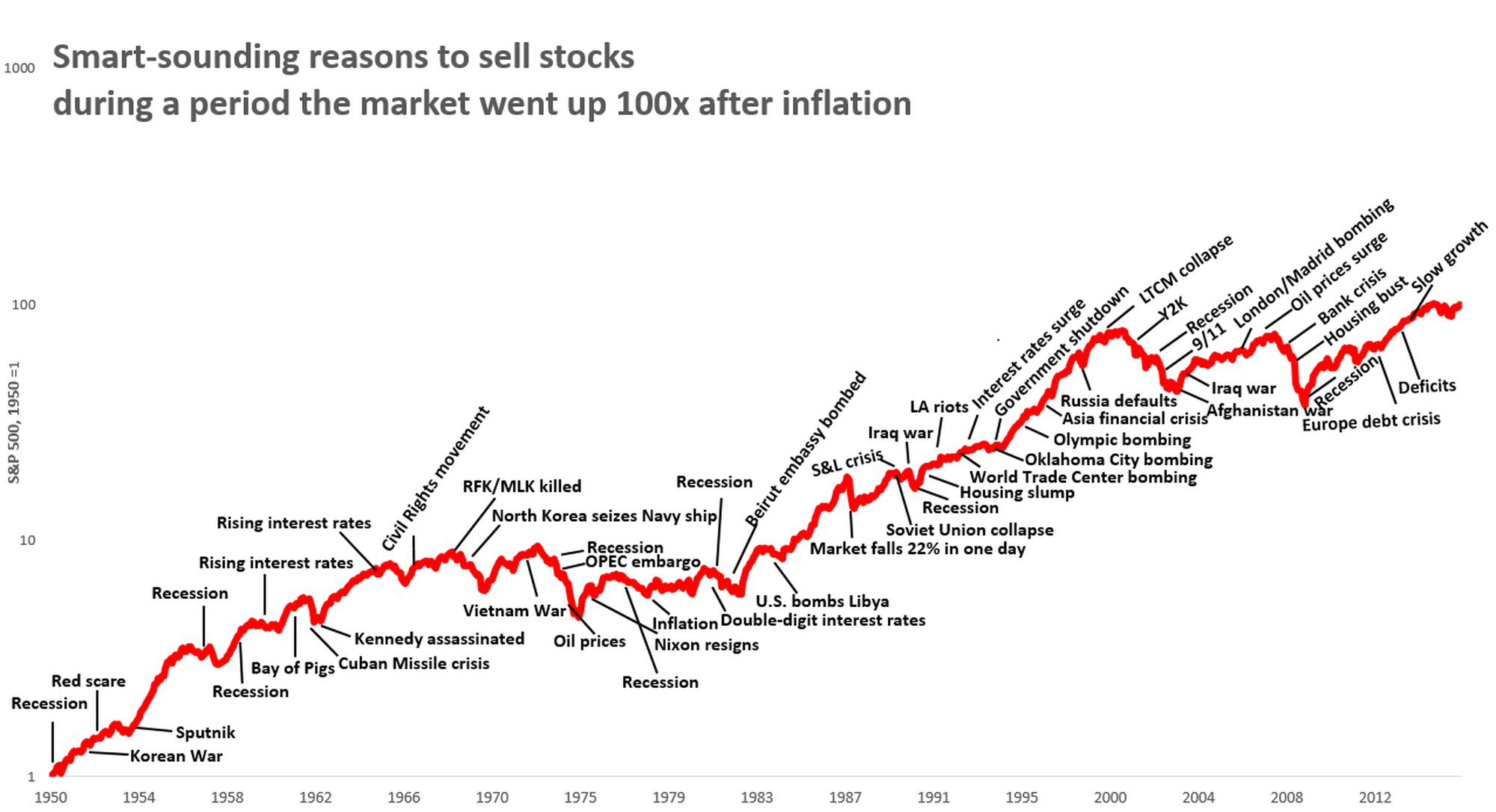
Za one koji žele ovde nešto smisleno da čuju, evo dva dijagrama da uvek postoje "pametni razlozi" za prodaju akcija i izlazak sa USA berze.
[/url]
Zaradio je ogroman bolji ljudi, u periodu 2015-2020 recimo naročito, posebno 2017. kada je bilo nemoguće izgubiti.
Međutim, sada kada je USA hegemonija konačno na izdahu, kada im se toliko štampanje para obija o glavu, kada gube rat "koji ne smeju da izgube" - sada se ZAISTA postavlja pitanje da li sa ovih nivoa američka berza može gore (o evropskim akcijama niko i ne razmišlja) - ili će balon konačno puknuti i sve se raspasti.
Neće trebati dugo vremena da to vidimo i sami.
[ Ivan Dimkovic @ 11.06.2024. 14:07 ] @
Citat:
sikira069:
Jedino sigurno je dati u Poštansku štedionicu na skoro 3% godišnje kamate koliko je bilo u martu na devizne uloge.
Ne verujem da te blue-chip akcije stalno rastu.
Nekada i padaju. To chip je baš pokeraški izraz.
Nema nicega pokeraskog parkiranjem novca u neki mutual fond koji prati NASDAQ ili NYSE, ili uraditi to isto sam investiranjem u portfolio akcija pojedinacnih firmi. Ljudi parkiraju svoje pare na 5-10+ godina i generalno ce proci bolje nego da su ih stavili u banku nisu nikakvi kockari vec racionalne individue koje pametnu raspolazu svojim novcem.
Potpuno je irelevantno to sto pojedinacne akcije skacu i padaju svakog dana ako je strategija dugorocna a ne kockanje. Ako mogu da zaboravim na taj novac u sledecih 10 ili 15 godina, sto bi me bila briga sto iz dana u dan vrednost akcija fluktuira? Ideja je upravo da ne razmisljas o tome - cista antiteza kockanju.
Sto se tice ocuvanja vrednosti investicija, nema nicega apsolutno sigurnog - to sto dobijas od banke na stednju moze biti manje od realne stope inflacije i na kraju ostajes sa manjom kupovnom moci nego kada si poceo. Ulaganje u benchmark akcije kao dugorocna strategija je nesto malo vise rizicno od stednje u banci zato sto moze da se desi da ako ti novac hitno treba da u tom momentu vrednost bude manja ali je taj rizik kompenzovan sa dobitkom koji je veci od stope inflacije i koji je sigurniji koliko duze taj novac drzis parkiran.
Ko ima toleranciju na rizik od 0% nece ulagati u bilo kakvu vrstu spekulativne investicije, ali je besmisleno nazivati dugorocno ulaganje u berzu kockanjem.
[ Nebojsa Milanovic @ 11.06.2024. 15:39 ] @
@Ivan
Lepo si napisao ali nemoj reći da si mislio da sikira to ozbiljno piše.
Od prvog dana, na oba nicka, cilj mu je isključivo da sruši svaki smislenu diskusiju na ES-u, i na moje zgražavanje, u tome je i uspeo.
Konačno je banovan ali kasno, prekasno, sada kada je uništio svaki smisao konstruktivne priče.
Apsolutno najgora stvar na ES-u je dozvoljavanje trolovima da namerno ruše konstruktivne diskusije.
Toga je ranije bilo više, ali postojao je jedan period čist od toga, do pojave sikire, kome se nije smelo dozvoliti da toliku štetu napravi.
[ MajorFatal @ 11.06.2024. 20:16 ] @
Citat:
Ivan Dimkovic:
Monetarna (trenutna) vrednost akcije je besmislen podatak bez ukupnog broja akcija (sto ti daje market cap) i fundamentalnih parametara poslovanja firme.
Pretpostavljam da svaki podatak može da bude besmislen kad je istrgnut iz konteksta. Vrednost akcije naravno da je bitan i smislen podatak za onog ko tu akciju hoće da kupi ..
Citat:
Mozes ti da emitujes koliko hoces akcija ali vrednost tvoje firme utvrdjuje trziste na osnovu pomenutih fundamentalnih parametara i prognoza kuda idu trziste i tvoja firma u njemu, pa bi se na bilo koju vrednost i broj akcija brojevi nivelisali na ocekivanje trzista u odnosu na realnost. Samu vrednost akcija odredjujes ne ti kao emiter, vec samo oni koji akcije kupuju i prodaju.
Pa dobro, na koji način se firme odlučuju za emitovanje kojeg broja akcija, jer je prilično očigledno da ako emituješ veći broj akcija manje će vredeti pojedinačna i obrnuto.
Citat:
TL;DR - vredis koliko su drugi spremni da plate.
Zanima koliko se vrednost neke firme poklapa sa platežnom moći te firme? Razgovor je počeo od toga da nvidia može da kupi auto industriju, a ja i dalje mislim da ne može, iako je na papiru vrednija .. ako su akcionari nvidije vlasnici biznisa možda oni mogu da kupe auto industriju? A to baš nije isto kao da je nvidija kupila? Evo ne znam sve mi zbrčkano.
Citat:
Kao firma, emitovanjem svojih akcija bez da se ista promeni umanjujes njihovu vrednost, dok kupovinom svojih akcija bez da se ista drugo menja im povecavas vrednost (neke firme to rade - vidi 'stock buyback', to je nesto sto je nekim firmama u USA strategija umesto isplate dividendi zato sto je poreski trenutno efikasnija).
Verovatno emitovanjem *dodatnih akcija. Spekulacija, vrednost firme na berzi možda ne govori mnogo o platežnoj moći.
[ MajorFatal @ 11.06.2024. 20:26 ] @
Citat:
djoka_l:
Zašto postavljaš besmislena pitanja?
Zar nisi čuo da ne postoje besmislena pitanja, samo besmisleni odgovori.. ? :)
Citat:
Da li je veći baja onaj milioner koji ima milion novčanica od 1 dolar ili onaj koji ima 10 hiljada od 100 dolara?
Isti su, ali moje pitanje nije bilo u tom smislu, nego više da li je bolje izaći iz kuće sa buđelarom punim sitnih apoena, ili sa dve - tri krupne novčanice, to je i dalje isto dok se ne ispostavi da ideš na svadbu, ili u kupovinu auta, baje su iste, ali bi bio manji baja ako krene sa sitnim apoenima u kupovinu auta jer bi mu trebao ceo šleper, slično bio bi manji sa dve tri krupne novčanice na svadbi jer bi brzo sve dao na muziku, pa ne bi imao za mladence, konobare, fotografije ..
Citat:
Cena akcije je potpuno nebitna, osim kao faktor koji se koristi da se pomnoži sa brojem akcija.
Bukvalno dva reda niže ti sam pišeš da je cena akcija ipak bitna kad su mali akcionari u pitanju, da ne boldujem.
Citat:
Osim toga, inicijalnu cenu pojedinačne akcije određuje firma koja izlazi na berzu, kasnije kretanje cene akcije diktira ponuda i potražnja na berzi.
Zašto bi se ponuda i potražnja ikad menjale ako je biznis stabilan i višedecenijski?
Citat:
Inicijalna cena je "vrednost apoena". Ima puno razloga da inicijalna cena bude mala, recimo 10 ili 100 jedinica.
Ako si ti mali akcionar i kupuješ akcije kao vid štednje, možda nemaš 1000 dolara da kupiš akciju od 1000 dolara, nego si uštedeo 500 dolara, pa možeš da kupiš 50 akcija koje pojedinačno vrede po 10 dolara.
Za velike investitore je potpuno nebitno koliko košta pojedinačna akcija, ali je za male bitno.
Bukvalno par redova iznad ti sam pišeš da je cena akcija totalno nebitna, osim da se pomnoži sa brojem akcija, tako da dogovori se pa kaži, da li je cena bitna ili nije?
[ Nebojsa Milanovic @ 11.06.2024. 21:25 ] @
@Major
Sve što si pitao je toliko bizarno-besmisleno da nije jasno da li stvarno toliko ne znaš, ili želiš da saznaš - ili samo troluješ.
Cena SVIH akcija na svetu zavisi PRVENSTVENO od makro-okruženja, kamatnih stopa i XXX drugih parametara, pa tek onda od stabilnosti biznisa, koji naravno mora da se podrazumeva (u suprotnosti je bankrot).
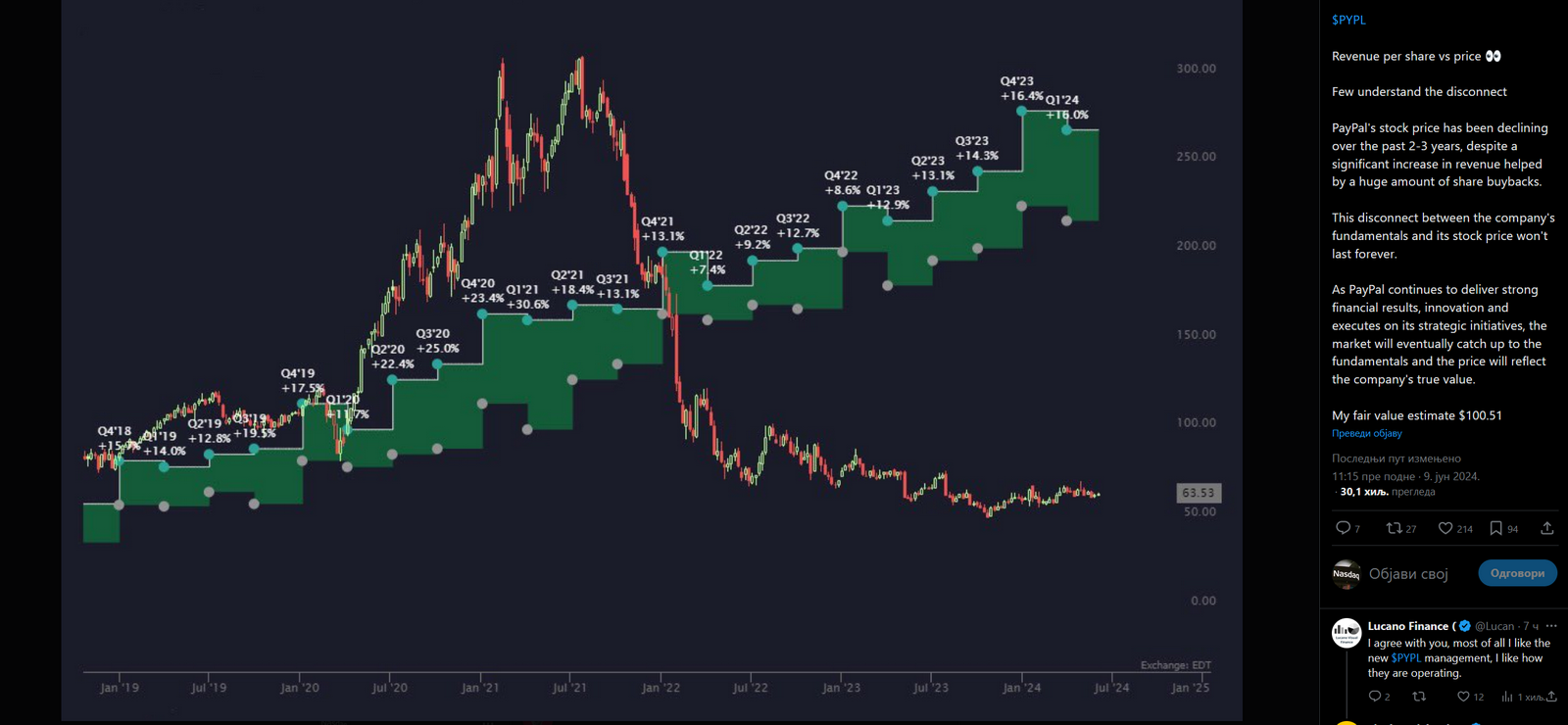
Evo ti primer firme koju svi znamo, Pejpal, ticker: PYPL.
Pogledaj koliko stabilno rastu i prihodi i poslovanje firme - a koliko cena akcije NEME VEZE sa tim.
Uzmi u obzir da je to oooogromna firma vredna 100+ milijardi dolara.
Kod manjih firmi sve to je još daleeeeko izraženije.
[ Shadowed @ 11.06.2024. 22:18 ] @
Citat:
MajorFatal: Zar nisi čuo da ne postoje besmislena pitanja, samo besmisleni odgovori.. ? :)
Tu mantru ponavljaju oni koji postavljaju besmislena pitanja sto ne znaci da je tacna.
[ MajorFatal @ 11.06.2024. 22:31 ] @
Tu "mantru" sam malopre izmislio, tako da teško da se ponavljala, mantra je da ne postoje glupa pitanja, to se često moglo čuti ..
Ne znači da je tačna, ali takođe nikog ne obavezuje da odgovara na glupa ili besmislena pitanja, samo preskoči što bi rekli ..
U konkretnom slučaju, konstatacija da je pitanje besmisleno je pokušaj uvrede, sa ciljem diskreditacije sagovornika, iz razloga nemanja argumenata ili neznanja da se odgovori na savršeno smisleno pitanje.
[ Shadowed @ 12.06.2024. 08:04 ] @
Ponavljaju i za besmislena i za glupa. To sto si ti sad nesto "izmislio", ne znaci da si prvi.
Kada postavis besmisleno pitanje konstatacija da je besmisleno nema nikakave veze sa diskreditovanjem, sam si se diskreditovao.
Inace je minimum 90% tvojih bilo pitanja bilo izjava i besmisleno i glupo. Nije problem ne odgovarati (kao sto ti najcesce i ne odgovaram sto i drugima preporucujem). Problem je u bacenom vremenu na citanje istih.
[ MajorFatal @ 12.06.2024. 08:39 ] @
Citat:
Shadowed: Ponavljaju i za besmislena i za glupa. To sto si ti sad nesto "izmislio", ne znaci da si prvi.
Ne ponavljaju, "nema glupih pitanja već ...itd" koriste pedagozi da ponutkaju i oslobode decu da postavljaju pitanja. "Nema besmislenih pitanja.." nikad ranije nisam čuo, ali nisam tvrdio ni da sam "prvi".
Citat:
Kada postavis besmisleno pitanje konstatacija da je besmisleno nema nikakave veze sa diskreditovanjem, sam si se diskreditovao.
Nije "kada", nego "ako". Ako postavim besmisleno pitanje zaista je tako kako ti kažeš, ali ako ne postavim onda nije.
Citat:
Inace je minimum 90% tvojih bilo pitanja bilo izjava i besmisleno i glupo. Nije problem ne odgovarati (kao sto ti najcesce i ne odgovaram sto i drugima preporucujem). Problem je u bacenom vremenu na citanje istih.
Fala ti za te lepe reči i procenu. Moram priznati da bi mogao biti problem ako tako procenjuješ. Imao sam i ja par njih za koje mi se činilo da je 90% onog što pišu upitnog kvaliteta, nije bilo lako ali uspeo sam da se istreniram da njihove postove jednostavno ne čitam. Zar ti nisi imao neku skriptu za ignorisanje korisnika? Ali ako bi je koristio onda nedostaje kontekst, ako se desi da neko odgovara baš na moju repliku. Jedino još mogu da ti ponudim da odsustvujem sa foruma, ako će ti to uštedeti dragoceno vreme?
[ miki069 @ 20.07.2024. 18:21 ] @
Što pada vrednost akcija NVIDIA?
Za 10 dana su sa 135 pale na 118.
Jel ovo dobar trenutak za kupovinu?
[Ovu poruku je menjao miki069 dana 20.07.2024. u 20:56 GMT+1]
[ miki069 @ 27.07.2024. 23:31 ] @
NVIDIA nastavlja pad.
Akcije pale na 113 dolara.
Pre 15 dana su bile 135 dolara.
I akcije AWS su za 15 dana pale sa 200 dolara na 180 dolara.
[ Nebojsa Milanovic @ 28.07.2024. 17:57 ] @
Nije to AWS nego Amazon
Pao je i on zbog jake korekcije na marketu poslednjih dana, a poenta mog posta je da će Nvidia u skorije vreme osetiti konkurenciju koju do sada nije imala.
[ miki069 @ 28.07.2024. 19:02 ] @
Amazon Web Services (skraćeno, AWS).
[ Nebojsa Milanovic @ 28.07.2024. 22:38 ] @
Haaalo, AWS je deo Amazona i nije izlistan na berzi
[ miki069 @ 29.07.2024. 14:35 ] @
Što se tiče akcija izgleda da je mnogo bitna ona poslovica da ne kune majka sina kada ide da se kocka, već ga kune kada ide da se vadi.
Klasično kockanje u kome samo brokeri zarađuju.
Obični ljudi samo gube.
[ miki069 @ 30.07.2024. 15:30 ] @
NVIDIA nastavlja pad.
Akcije pale na 107.4 dolara.
[ Nebojsa Milanovic @ 30.07.2024. 15:36 ] @
Paper hands paniče i prodaju - pametni se tovare. Uvek bilo.
[ djoka_l @ 30.07.2024. 15:42 ] @
Akcije NVIDIA su naduvane.
Ceo AI balon se pomalo izduvava, ali NVIDIA je mnooogo dobra kompanija.
Prave nenormalan profit, tako da ovo više liči na pad na realnu vrednost nego što predstavlja stvarni problem kompanije.
[ miki069 @ 30.07.2024. 17:40 ] @
Nvidia akcije padaju svake sekunde.
Sada su 104.3 dolara.
Ništa od akceleratora? Blue-chip?
Market chap?
Sve prenaduvano i nerealno.
Treba imati m.da pa kupiti.
Što reče Đole "povukao je damu na 18 mrtav ladan...".
[ miki069 @ 31.07.2024. 13:44 ] @
Opet pada vrednost akcija.
Sada je 103.7 $.
[ miki069 @ 31.07.2024. 18:25 ] @
Sada su akcije porasle na 115.8 $.
[ miki069 @ 31.07.2024. 22:33 ] @
Opet rast na 116.95 $.
Sutra počinje retrogradni Merkur.
Najverovatnije akcije idu dole.
[ Nebojsa Milanovic @ 01.08.2024. 01:25 ] @
Večeras u after hours trgovanju cena NVDA akcija je 122 dolara.
Šta sam rekao:
Citat:
Nebojsa Milanovic: Paper hands paniče i prodaju - pametni se tovare. Uvek bilo.
Tačno to.
Takođe i sa CRWD akcijama je bilo tačno onako kako sam rekao, sutra ću napisati.
[ miki069 @ 01.08.2024. 17:15 ] @
Retrogradni Merkur čini svoje.
Akcije pale na 113.42 $.
Može još gore.
Palo na 108.4 $.
[Ovu poruku je menjao miki069 dana 01.08.2024. u 20:45 GMT+1]
[ Nebojsa Milanovic @ 01.08.2024. 21:17 ] @
To je zbog veoma oštrog pada celog marketa, pojava nema veze sa NVDA akcijama.
Oporaviće se.
[ Nebojsa Milanovic @ 02.08.2024. 00:40 ] @
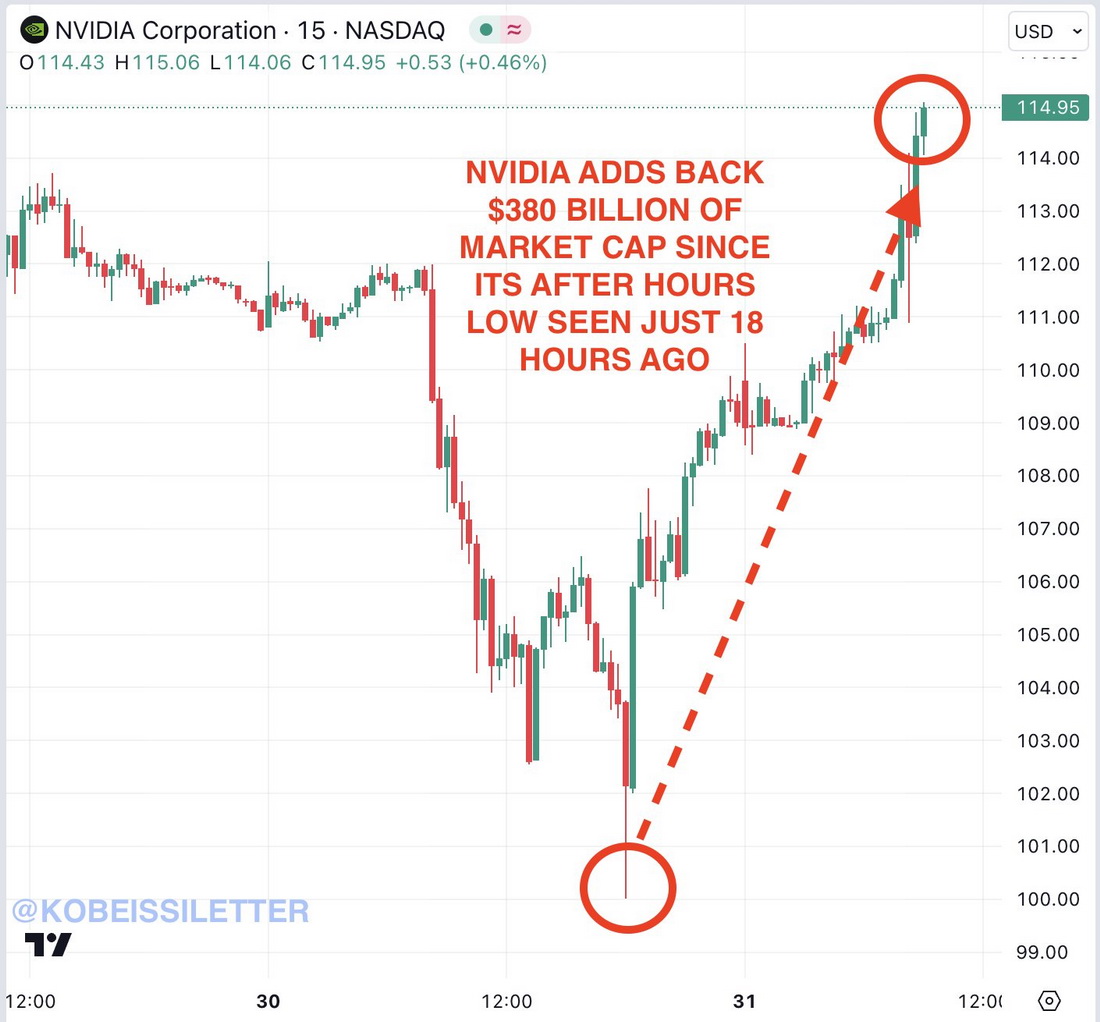
Citat:
Nvidia, $NVDA, the third largest company in the world is trading like a penny stock.
Since its after hours low seen just 18 hours ago, Nvidia has added $380 BILLION of market cap.
In other words, Nvidia has added as much market cap as the entire value of Costco, $COST, in 18 hours.
This comes after the stock erased $1 TRILLION of market cap over the last 5 weeks.
Big tech stocks are throwing around trillions of Dollars of market cap in a matter of hours.
Truly insane.
[ Nebojsa Milanovic @ 02.08.2024. 00:54 ] @
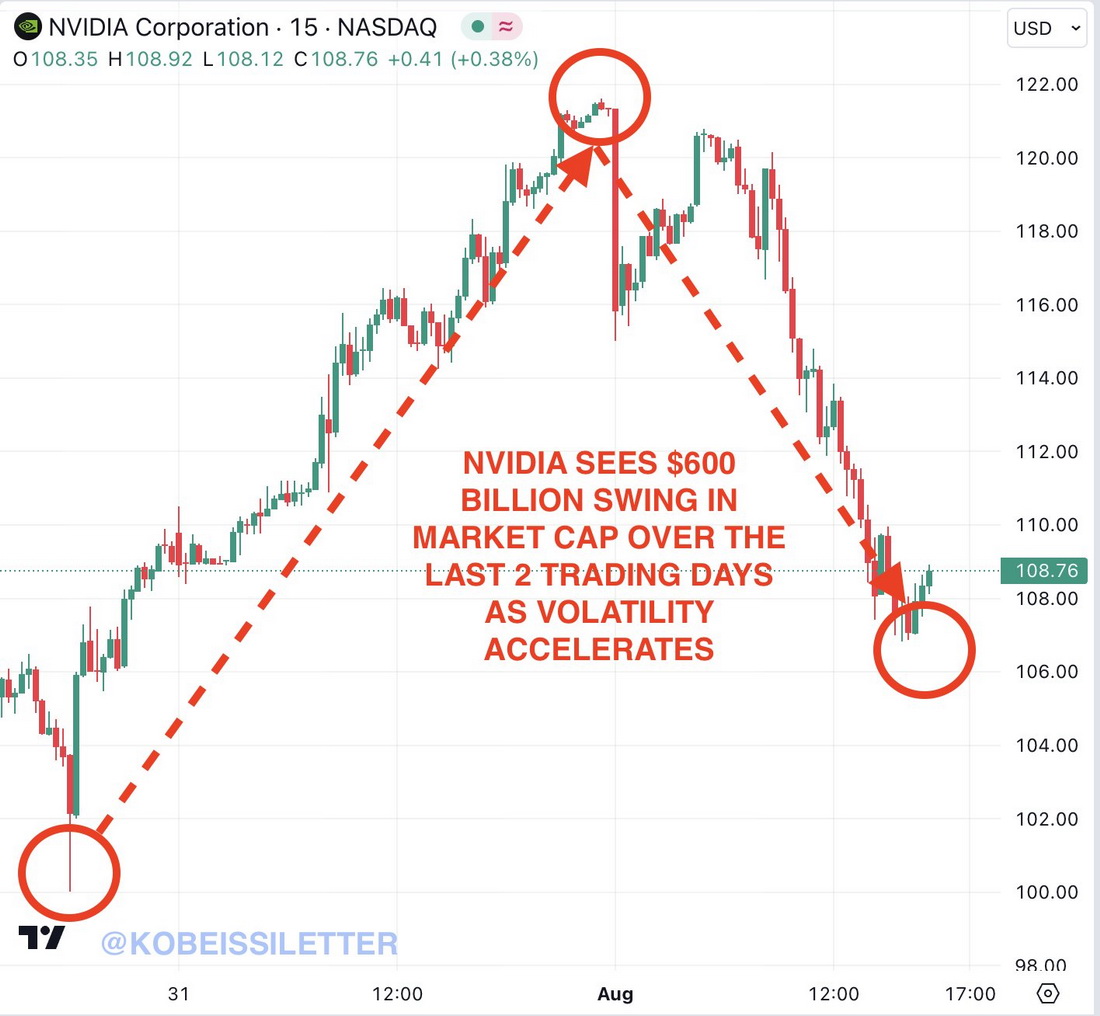
Citat:
Yesterday, Nvidia, $NVDA, broke the all time record for most market cap added by a stock in a single day, adding +$330 billion.
Today, the stock has erased ~$270 billion of market cap since its high seen this morning.
That's a $600 BILLION swing in market cap in just 2 trading days.
The 3rd largest public company in the world is officially trading like a meme stock.
[ Nebojsa Milanovic @ 02.08.2024. 22:37 ] @
Citat:
Nebojsa Milanovic:
To je zbog veoma oštrog pada celog marketa, pojava nema veze sa NVDA akcijama.
Trenutna vrednost akcije je 107 $.
Pre 20 dana je akcija vredela 135 $.
Ne razumem šta se tu oporavilo?
Ko je tada kupio akcije izgubio je preko 20%.
[ mpman @ 04.08.2024. 11:25 ] @
Trenutno mi se čini da ono što se naziva danas veštačkom inteligencijom nije ono za šta se predstavlja. U pitanju su samo veliki, specijalizovani modeli mašinskog učenja sa ogromnim bazama podataka. Ako sam dobro razumeo kako sve to funkcioniše, mašinsko učenje se na neki način oslanja na metaheuristiku i evolucione optimizacione algoritme pri čemu se nalazi način da se kvantifikuje određena specijalizovana stvar na osnovu koje se definišu težinski koeficijenti koji se minimizuju kroz niz iteracija dok se ne iscrpi početna baza podataka, pa se ti isti težinski koeficijenti primenjuju nad novim modelima.
Ovo je problem i ovo nije u suštini veštačka inteligencija u smislu u kojem mi mislimo da jeste. Jer ekstrapolacija podataka ne mora nužno da bude uspešna nezavisno od toga na čemu je model treniran, što znači da je jošuvek ljudska intervencija neophodna. Trenutno stanje veštačke inteligencije je da ona ne može da smisli ništa novo, već kombinuje stvari na osnovu već postojećih primera. Ona ne razume šta radi, o čemu piše, šta slika, već na osnovu kaznenih funkcija koje negativno utiču na minimizaciju težinskih koeficijenata i konačne funkcije cilja dolazi do određenih rezultata. To znači da ona suštinski ne može da uvidi nove šablone i kreira nove stvari, već može samo da radi sa onim na čemu je model treniran.
That being said... Veliki broj poslova upravo to i zahteva. Kombinovanje postojećih rešenja da bi se nešto rešilo, napisalo, nacrtalo. Takvi poslovi su sada ugroženi, ali opet oni koji znaju šta rade i koji su dobri u svom poslu ostaće da "hrane" i kontrolišu algoritam. Što se autonomne vožnje tiče, osim dobrog marketinga koji je gospodin Mask odradio, od toga nema ništa. Jer je vožnja jedan od onih slučajeva gde greške u ekstrapolaciji mogu biti pogubne. Ona može biti dovoljno dobra u 80% slučajeva, ali u 20% slučajeva će koštati života. Jer vožnja je jedan od onih stvari u kojoj će se uvek javljati pojave koje niko nije mogao da predvidi u datim okolnostima.
Ono što je strašno i što je opasno jeste to što se ljudi opuštaju. Volan u novim vozilima nema vizičku konekciju sa točkovima. Automobili su visoko uvezani tehnološki sistemi koji mogu da komuniciraju jedni s drugima. Do sada je bilo x skandala gde su već sadašnji automobili špijunirali svoje korisnike, a automobilske kompanije su prodavale podatke o tome gde su njihovi korisnici vozili, kada, kako i koliko osiguravajućim kućama koje su posle na osnovu toga podizale premiju za osiguranje automobila. Osim ogromne invazije privatnosti, zamislite koliko će lako biti rešiti se političkih protivnika zbog "baga u sistemu" ili "loše procene veštačke inteligencije".
[ miki069 @ 04.08.2024. 12:08 ] @
Što se Matematike tiče ne vidim neki pomak.
Sve što može brute-force je davno isprogramirano.
Gde god mora da se bude kreativan nema pomoći od računara.
O tome da će zameniti profesora tek nema šanse.
[ mpman @ 04.08.2024. 12:24 ] @
I što se tiče upravljanja... Većina stvari koje se brendiraju u poslenje vreme kao "VI" su zapravo samo sistemi automatskog upravljanja sa direktnom kompenzacijom poremećaja, tema razrađena kod nas još osamdesetih, u svetu i ranije. Razlika je samo u tome što se mehaničke komponente menjaju elektronskim, a komunikacija sa sistemima se odvija na daljinu. Mada, složićete se, nije neka razlika.
[ B3R1 @ 04.08.2024. 13:44 ] @
Citat:
mpman:
Trenutno mi se čini da ono što se naziva danas veštačkom inteligencijom nije ono za šta se predstavlja.
Zavisi koga pitas. Ako citas clanke koje su pisali likovi koji zavrse smer zurnalistike na onom smehotresnom fakultetu na Vozdovcu ... ili na nekome jos smehotresnijem privatnom fakultetu - onda je odgovor: da, to svakako nije ono kako mali Perica (to jest taj jadnicak od "studenta") shvata AI.
Citat:
U pitanju su samo veliki, specijalizovani modeli mašinskog učenja sa ogromnim bazama podataka. Ako sam dobro razumeo kako sve to funkcioniše, mašinsko učenje se na neki način oslanja na metaheuristiku i evolucione optimizacione algoritme pri čemu se nalazi način da se kvantifikuje određena specijalizovana stvar na osnovu koje se definišu težinski koeficijenti koji se minimizuju kroz niz iteracija dok se ne iscrpi početna baza podataka, pa se ti isti težinski koeficijenti primenjuju nad novim modelima.
Bravo! Ovo si bas lepo sazeo u jednu recenicu. To funkcionise bas tako.
Takodje, masinsko ucenje nije nova stvar. Nekolicina mojih kolega su jos pre 25 godina doktorirali na temu primene masinskog ucenja u raznim oblastima i u to vreme ti doktorati su bili hit. Ljudi su te PhD radili mahom u Americi, ali bilo je i onih koji su to odradil iu Srbiji. Ono sto jeste novo je LLM - odnosno slozeni modeli govornog jezika. Takva stvar nije bila moguca pre 25 godina iz prostog razloga sto u to vreme nismo imali dovoljno mocan hardver na kome bi se to vrtelo. LLM modeli su gradjeni decenijama, a ovo sto vidis danas je samo rezultat svih tih istrazivanja koja su radjena do sada.
Problem je u tome sto ljudi postavljaju znak jednakosti iza jedne siroke naucno-tehnoloske oblasti zvane vestacka inteligencija (AI / VI), masinskog ucenja, neuralnih mreza i LLM, a sva ta 4 pojma, iako srodna medju sobom, su ipak totalno odvojene stvari. Bas kao sto je velika vecina ljudi (cak i strucnjaka) 90-ih pogresno stavljala znak jednakosti izmedju Interneta i Weba, a danas to rade isto s drustvenim medijima i drustvenim mrezama ... pa kada npr. Instagram ne radi zbog nekog tehnickog problema u mrezi Meta, na medijskim portalima se pojave naslovi tipa: "Pao Internet". Ljudi, nije pao Internet, on je jos uvek zivahan i koristim ga upravo ... a to sto vi ne mozete da lajkujete gluposti, to je vas problem.
Ali objasni ti to skolarcima smehotresne novinarske skolice s Vozdovca ... doduse, njima svaki dan "Internet gori od Severiniih slika s plaze" ... a "Djokovic je zagrmeo". Internet ne gori, nije zapaljiv. Ljudi ne grme. Naucite vec jednom !!! :-)))
Citat:
Trenutno stanje veštačke inteligencije je da ona ne može da smisli ništa novo, već kombinuje stvari na osnovu već postojećih primera.
Tako je.
Citat:
Veliki broj poslova upravo to i zahteva.
Nazalost, i to je tacno. U vecini velikih korporacija na zapadu mnogi ljudi rade bas takve stvari - npr. na osnovu nekih brojeva (najcesce finansijskih rezultata, ali i drugih KPI) u Excelu on pise izvestaj za svoje menadzere, a kada mu menadzeri sugerisu sta treba uraditi on pise detaljna uputstva svojim podredjenima. Drugim recima, izigrava protocni bojler. Cim vidis firmu u kojoj imas npr. 9 nivoa menadzera od krajnjeg izvrsioca do CEO znaj da barem cetvoro u tom lancu radi najobicniji I/O, bez grama mozga. Ameri to zovu paper-pushers. I sto je najgore, ti poslovi su neretko izuzetno dobro placeni!
Citat:
Takvi poslovi su sada ugroženi
Nisu. Samo ce morati mnogo vise da rade. Koriscenjem AI, naravno. I umesto aktivne uloge u stvaranju necega dobice pasivnu ulogu kontrologa tog necega sto je AI napravila. Problem ce nastati onda kada se od njih bude zahtevalo da umesto npr. 3-4 projekta nedeljno sada rade na 30-40, a mozda i na 300-400 istovremeno. Jer tu je AI. Bas kao sto se nekada ocekivalo da jedan projekat od nekih ~100 stranica teksta drukas na nekoj raspaloj pisacoj masini nedeljama, a mozda i mesecima i radis taj jedan ... dok danas uzmes ono sto su ti radile kolege, copy/paste - pljas, gotovo, sledeci ... i to je normalno, reuse - recycle ... I to je danas moguce zahvaljujuci Wordu i njegovom <Ctrl-C><Ctrl-V>.
Sutra ce se zahtevati mnogo vise, jer ce cukanje teksta u Wordu zameniti autogenerisanje dokumenta AI-em.
Citat:
Osim ogromne invazije privatnosti, zamislite koliko će lako biti rešiti se političkih protivnika zbog "baga u sistemu" ili "loše procene veštačke inteligencije".
Ne znam za politiku, time se ne bavim. Ali znam za su mnoge kompanije pocele da koriste AI u procesu zaposljavanja novih radnika, tako da neko ko je mozda izuzetno iskusan u svom poslu, a u CV nema naglasene kljucne reci na koje je AI softver istreniran, nece proci prvi filter i njegov CV nece ni stici do hiring menadzera. Ali ni radnici nisu nista bolji. Poceli su da koriste AI za pisanje CV i sada svi CV-evi lice jedan na drugi. :-)
Medjutim, ima jedna stvar u kojoj AI nece moci da zameni ljude jos prilicno dugo.
Na departmanu Telekomunikacija lozanskog fakulteta EPFL pre 50 godina predavao je izvesni profesor Juillard. U predgovoru svog udzbenika profesor je napisao sledece reci:
Citat:
L’ingénieur est un type qui sait ce qu’il peut négliger
U prevodu: inzenjer je lik koji zna sta se moze zanemariti
U knjizi potom sledi prelep predgovor, za koji bih vam savetovao da ga procitate, ako treba koristite i Google Translate. Uvek se odusevljavam iznova kada procitam taj tekst. Pritom, stari profesor nije bas bio 100% originalan i verovatno je bio inspirisan svojim zemljakom, autorom Malog princa, koji je rekao nesto slicno - da se perfekcija ne postize onda kada nemas vise sta da dodas, vec kada vise nemas sta da oduzmes.
I mislim da je upravo ta vestina zanemarivanja, odnosno aproksimacije ono sto ce nas sigurno jos dugo razlikovati od masine.
[ mpman @ 04.08.2024. 16:43 ] @
Citat:
Nisu. Samo ce morati mnogo vise da rade. Koriscenjem AI, naravno. I umesto aktivne uloge u stvaranju necega dobice pasivnu ulogu kontrologa tog necega sto je AI napravila. Problem ce nastati onda kada se od njih bude zahtevalo da umesto npr. 3-4 projekta nedeljno sada rade na 30-40, a mozda i na 300-400 istovremeno. Jer tu je AI. Bas kao sto se nekada ocekivalo da jedan projekat od nekih ~100 stranica teksta drukas na nekoj raspaloj pisacoj masini nedeljama, a mozda i mesecima i radis taj jedan ... dok danas uzmes ono sto su ti radile kolege, copy/paste - pljas, gotovo, sledeci ... i to je normalno, reuse - recycle ... I to je danas moguce zahvaljujuci Wordu i njegovom <Ctrl-C><Ctrl-V>.
Sutra ce se zahtevati mnogo vise, jer ce cukanje teksta u Wordu zameniti autogenerisanje dokumenta AI-em.
Skoro je bilo velikih otpuštanja u određenim novinarskim firmama gde su radnici zamenjeni LLM-om, tj. OpenAI-jem ko god da je nalepio svoj brend preko toga. Na to sam mislio kad sam rekao da su ti poslovi sada ugroženi. Čim se poveća "produktivnost" "novinara" umanjuje se potreba za dodatnim "novinarima". Ako je cilj 600 članaka mesečno, lupam, i za to je bez upotrebe ovih tehnologija potrebno, opet lupam, 60 ljudi... Ako tu mesečnu kvotu uz korišćenje tehnologija može da ispuni 20 ljudi, to znači da je 40 ljudi višak, tj. dobijaju otkaz. Ne kažem da će se radna mesta ugasiti, već će biti potrebno manje ljudi.
Oko ostalog se slažemo. Jako lep citat i predgovor :)
[ Nebojsa Milanovic @ 04.08.2024. 23:38 ] @
Citat:
miki069:
Trenutna vrednost akcije je 107 $.
Pre 20 dana je akcija vredela 135 $.
Ne razumem šta se tu oporavilo?
Ko je tada kupio akcije izgubio je preko 20%.
Aham..poenta je u tome što niko normalan tu akciju ne kupuje na All-time-high
Pametni su kupovali, pa malo je reći na vreme, dobri su samo oko 300 puta...
p.s. sada je stvarno kasno, rast sa ovih nivoa je upitan...
[ Ivan Dimkovic @ 05.08.2024. 17:40 ] @
Citat:
mpman:
Trenutno mi se čini da ono što se naziva danas veštačkom inteligencijom nije ono za šta se predstavlja. U pitanju su samo veliki, specijalizovani modeli mašinskog učenja sa ogromnim bazama podataka. Ako sam dobro razumeo kako sve to funkcioniše, mašinsko učenje se na neki način oslanja na metaheuristiku i evolucione optimizacione algoritme pri čemu se nalazi način da se kvantifikuje određena specijalizovana stvar na osnovu koje se definišu težinski koeficijenti koji se minimizuju kroz niz iteracija dok se ne iscrpi početna baza podataka, pa se ti isti težinski koeficijenti primenjuju nad novim modelima.
Ovo je problem i ovo nije u suštini veštačka inteligencija u smislu u kojem mi mislimo da jeste. Jer ekstrapolacija podataka ne mora nužno da bude uspešna nezavisno od toga na čemu je model treniran, što znači da je jošuvek ljudska intervencija neophodna. Trenutno stanje veštačke inteligencije je da ona ne može da smisli ništa novo, već kombinuje stvari na osnovu već postojećih primera. Ona ne razume šta radi, o čemu piše, šta slika, već na osnovu kaznenih funkcija koje negativno utiču na minimizaciju težinskih koeficijenata i konačne funkcije cilja dolazi do određenih rezultata. To znači da ona suštinski ne može da uvidi nove šablone i kreira nove stvari, već može samo da radi sa onim na čemu je model treniran.
That being said... Veliki broj poslova upravo to i zahteva. Kombinovanje postojećih rešenja da bi se nešto rešilo, napisalo, nacrtalo. Takvi poslovi su sada ugroženi, ali opet oni koji znaju šta rade i koji su dobri u svom poslu ostaće da "hrane" i kontrolišu algoritam. Što se autonomne vožnje tiče, osim dobrog marketinga koji je gospodin Mask odradio, od toga nema ništa. Jer je vožnja jedan od onih slučajeva gde greške u ekstrapolaciji mogu biti pogubne. Ona može biti dovoljno dobra u 80% slučajeva, ali u 20% slučajeva će koštati života. Jer vožnja je jedan od onih stvari u kojoj će se uvek javljati pojave koje niko nije mogao da predvidi u datim okolnostima.
Ono što je strašno i što je opasno jeste to što se ljudi opuštaju. Volan u novim vozilima nema vizičku konekciju sa točkovima. Automobili su visoko uvezani tehnološki sistemi koji mogu da komuniciraju jedni s drugima. Do sada je bilo x skandala gde su već sadašnji automobili špijunirali svoje korisnike, a automobilske kompanije su prodavale podatke o tome gde su njihovi korisnici vozili, kada, kako i koliko osiguravajućim kućama koje su posle na osnovu toga podizale premiju za osiguranje automobila. Osim ogromne invazije privatnosti, zamislite koliko će lako biti rešiti se političkih protivnika zbog "baga u sistemu" ili "loše procene veštačke inteligencije".
Problem sa terminom "vestacka inteligencija" je to sto ne znamo zapravo sta je inteligencija uopste, prirodna ili ne.
Znaci termin koji nema kompletno objasnjenje iz prvih pricipa (a ni iz 'petih' principa) je "nalepljen" na nesto drugo zato sto 'lici' u nekom povrsinskom smislu.
Ali na kraju krajeva, pitanje terminologije je sekundarna stvar - glavno pitanje je sta neka stvar resava (ili ne).
[ mpman @ 05.08.2024. 21:25 ] @
Citat:
Ivan Dimkovic: Problem sa terminom "vestacka inteligencija" je to sto ne znamo zapravo sta je inteligencija uopste, prirodna ili ne.
Inteligencija jeste definisana, ali nije mehanizam njenog funkcionisanja.
Citat:
Ivan Dimkovic:Znaci termin koji nema kompletno objasnjenje iz prvih pricipa (a ni iz 'petih' principa) je "nalepljen" na nesto drugo zato sto 'lici' u nekom povrsinskom smislu.
Ali na kraju krajeva, pitanje terminologije je sekundarna stvar - glavno pitanje je sta neka stvar resava (ili ne).
Nije to ništa sporno, sporno je što Bogovi marketinga u poslednje vreme svuda ubacuju "AI" u nešto što nema mnogo veze samom veštačkom inteligencijom. To je, na neki način, dezinformisanje potrošača. Pominjem Maska jer je Tesla skoro bila u žiži oko povlačenja tvrdnji da će svi automobili biti u potpunosti sposobni za automatsku vožnju bez vozača, što ovakvi modeli u narednih ko zna koliko decenija neće biti u stanju da rade. Prodali su "beta program" bez ikakvih izgleda da će ljudi ikad dobiti finalni proizvod, a već kupljeni automobili kojima je garantovano da će moći to da koriste su stari već 5+ godina i najverovatnije nikad neće doživeti da uživaju u autonomnoj vožnji koja je bila jedna od stavki zbog kojih su kupili taj proizvod. Obmana potrošača. U suštini, meni smeta pogrešan marketing. I što se ljudima tim terminom daje pogrešna ideja šta to oni tačno kupuju.
[ djoka_l @ 06.08.2024. 13:02 ] @
Citat:
Inteligencija jeste definisana, ali nije mehanizam njenog funkcionisanja.
To nije tačno. Ne postoji generalno prihvaćena definicija inteligencije.
Još manje postoji generalno prihvaćena definicija veštačke inteligencije.
Čak i ako uzmemo najlabavije OPISE šta inteligencija obuhvata, onda ne postoji nikakva VEŠTAČKA INTELIGENCIJA.
Ako tvrdiš suprotno, da li je spam filter VI? Da li je antivirus VI? Da li je svaki program za igranje šaha VI? Da li je ELIZA VI?
[ Ulfsaar @ 06.08.2024. 13:08 ] @
Citat:
Inteligencija jeste definisana, ali nije mehanizam njenog funkcionisanja.
Kao i da je svest samo deo tog glavnog pitanja. U tom slučaju bi stvaranje mašina koje mogu da nas zamene u svemu verovatno bilo lakše za dostizanje.
Skoro je izašao jedan eksperimentalni rad koji ukazuje da kvantna teorija svesti Penroza i Hamerofa možda i nije za odbacivanje. Svest je prema toj teoriji ne deo pitanja inteligencije, nego fundamentalna vučna sila koja živim organizmima daje volju za životom (i na nivou molekula). To je sloj ispod mreže neurona koji neuroni koriste kad god postoje, ali on funkcioniše i u organizmima gde ih nema. Meni kao laiku izgleda da je to baš ono što i nedostaje današnjoj veštačkoj inteligenciji da bi bila "čovekolika". Ako bi ova teorija bila tačna, onda bi nam pravljenje te prave veštačke inteligencije potencijalno bilo veoma zakomplikovano.
[ Ivan Dimkovic @ 06.08.2024. 14:12 ] @
Teorija svesti Penroza i Hamerofa nije kvantna u nekom kanonicnom smislu, zato sto ukljucuje stvari koje nisu eksperimentalno potvrdjenje i nisu deo potvrdjene kvantno-mehanicke teorije (u stvari jos gore - postoje prilicni problemi koje bi morali da rese / objasne, ali to je vec solidan offtopic).
Ali to zapravo nije ni bitno - sve i da je ta teorija tacna, to ne znaci da je primarni mehanizam te teorije odgovoran za "svest".
Takodje, ne znaci ni da je to jedini moguci mehanizam odgovoran za "svest".
A cak i da sve to zanemarimo, ne sledi nuzno da su inteligentno ponasanje i svest identicna pojava ili nerazdvojne pojave, tj. da je za inteligentno ponasanje nuzno posedovanje svesti.
TL;DR - u kontekstu diskusije, ne menja nista.
[ mpman @ 06.08.2024. 15:11 ] @
Zanimljiva je tema za diskusiju :D
Citat:
djoka_l:
Citat:
Inteligencija jeste definisana, ali nije mehanizam njenog funkcionisanja.
To nije tačno. Ne postoji generalno prihvaćena definicija inteligencije.
"Human intelligence is, generally speaking, the mental quality that consists of the abilities to learn from experience, adapt to new situations, understand and handle abstract concepts, and use knowledge to control an environment. However, the question of what, exactly, defines human intelligence is contested, particularly among researchers of artificial intelligence, though there is broader agreement that intelligence consists of multiple processes, rather than being a single ability." [1]
Veštačka inteligencija je nešto što oponaša prirodnu inteligenciju. LLM-ovi koji se trenutno plasiraju i reklamiraju kao veštačka inteligencija nemaju glavne aspekte ovih definicija. Ne mogu se prilagoditi novim situacijama, novim okruženjima, ne razumeju materiju i ne mogu da razmišljaju niti barataju sa apstraktnim stvarima.
Citat:
djoka_l:Još manje postoji generalno prihvaćena definicija veštačke inteligencije.
Čak i ako uzmemo najlabavije OPISE šta inteligencija obuhvata, onda ne postoji nikakva VEŠTAČKA INTELIGENCIJA.
Ako tvrdiš suprotno, da li je spam filter VI? Da li je antivirus VI? Da li je svaki program za igranje šaha VI? Da li je ELIZA VI?
Nije spam filter VI, niti antivirus, niti programi za igranje šaha, a bome nije ni ChatGTP, Bing Copilot, AI Pin, Samsung AI i slični. Ako su bar četiri poslednja sa AI u naslovu "veštačka inteligencija", onda su i rezultati gugl pretrage bili, gugl adsensa, preporuke na youtube-u, spoitfy-u... A oni to nisu. To su algoritmi pravljeni za specifičnu stvar i to i rade, kao što su to i LLM-ovi.
Citat:
Ulfsaar:
Citat:
Inteligencija jeste definisana, ali nije mehanizam njenog funkcionisanja.
U suštini, nije problem definicija. Jer ako uzmemo da inteligencija ne opisuje jednu pojavu, jednu osobinu, već više osobina i mogućnosti, onda razlaganje svake od ovih mogućnosti pojedinačno i njihovim kombinovanjem može da se dobije nešto što liči na inteligenciju. Problem je što mehanizam iza tih osobina nije razrađen. Takođe jedan od vodećih naučnika u ovom polju je skoro dao jedan primer. Parafraziraću: "Ćerku sam hteo da naučim da vozi tako što bih joj puštao 100 000 h video snimaka o vožnji. Prvo se naljutila na mene, a onda je sa instruktorom za manje od 20h savladala bez problema." Jako je teško definisati šta znači razumevanje, što je na neki način i prepreka za rešavanje problema veštačke inteligencije.
Citat:
Ulfsaar:
Kao i da je svest samo deo tog glavnog pitanja. U tom slučaju bi stvaranje mašina koje mogu da nas zamene u svemu verovatno bilo lakše za dostizanje.
Skoro je izašao jedan eksperimentalni rad koji ukazuje da kvantna teorija svesti Penroza i Hamerofa možda i nije za odbacivanje. Svest je prema toj teoriji ne deo pitanja inteligencije, nego fundamentalna vučna sila koja živim organizmima daje volju za životom (i na nivou molekula). To je sloj ispod mreže neurona koji neuroni koriste kad god postoje, ali on funkcioniše i u organizmima gde ih nema. Meni kao laiku izgleda da je to baš ono što i nedostaje današnjoj veštačkoj inteligenciji da bi bila "čovekolika". Ako bi ova teorija bila tačna, onda bi nam pravljenje te prave veštačke inteligencije potencijalno bilo veoma zakomplikovano.
Iskreno, ne bih u ovo mešao svest i ne verujem da to nedostaje današnjoj inteligenciji, već razumevanje. Kada mašina bude mogla da razume koncepte, objekte, boje, zvukove, ideje, onda će razumeti i probleme, a samim tim će biti jednostavnije doći do nekog rešenja. Svakako daleko smo od toga. Svakako, LLM koji se maskira kao inteligencija, po meni bar, a nisam ni jedini u naučnoj zajednici, nije veštačka inteligencija.
Edit: Gledam u poruku i ne vidim gde grešim u linkovanju.
[ Ivan Dimkovic @ 06.08.2024. 16:11 ] @
Uh... I "razumevanje" je jos jedan nezgodan pojam.
Probaj da ga primenis na biologiju, mozes lako da dodjes do istog dead-enda kao za LLM... imas neku hrpu neurona sa sinaptickim receptorima razbacanim po dendritnom drvecu. Konfiguracija tih receptora i njihov broj su manjim delom genetski odredjeni a mnogo vecim delom... iskustveno.
Kad neko kaze da "razumemo" nesto, kontra argument slican tom LLM argumentu bi bio - to je samo termin koji smo naucili, sam proces nije nista drugo nego neko premestanje molekula / jonskih kanala / stagod...
Mislim da takva redukcija nema smisla ni u jednom ni u drugom slucaju, ali to je samo moje misljenje.
Citat:
arafraziraću: "Ćerku sam hteo da naučim da vozi tako što bih joj puštao 100 000 h video snimaka o vožnji. Prvo se naljutila na mene, a onda je sa instruktorom za manje od 20h savladala bez problema." Jako je teško definisati šta znači razumevanje, što je na neki način i prepreka za rešavanje problema veštačke inteligencije.
ALI hej... da bi ta devojka naucila da vozi za 20h, pre toga je njen nervni sistem bio treniran 24/7 od rodjenja, zar ne?
Mada ima tu razlika - ljudski mozak je u stanju da radi 'one shot' ucenje sa dramaticno malo stimulusa i da to ostane upamceno celi zivot. Jedno od mogucih objasnjenja za taj kapacitet je >drasticno< veci 'prostor' za reprezentaciju bioloske neuronske mreze (nesto tipa 100 milijardi neurona * hiljade ili desetine hiljada sinaptickih receptora + dramaticno veci dinamicki opseg zbog puke cinjenice da pricamo o biohemiji).
Vestacke neuronske mreze nemaju ni izbiliza takav kapacitet, plus kolicina 'stimulusa' kojom se treniraju je pateticna u odnosu na... bivanje zivim (samo kvantifikovati kolicinu informacija koju nervni sistem primi u toku svakog dana zivota i koja konstantno menja konfiguraciju)
[ Ulfsaar @ 11.08.2024. 12:57 ] @
Citat:
Ivan Dimkovic:
A cak i da sve to zanemarimo, ne sledi nuzno da su inteligentno ponasanje i svest identicna pojava ili nerazdvojne pojave, tj. da je za inteligentno ponasanje nuzno posedovanje svesti.
I nisu nerazdvojne, LLM često pokazuje inteligentno ponašanje. Ne vidim zašto se tačni odgovori koje daje ne bi mogli tako okarakterisati. Ali,
LLM ih ne daje sam od sebe, nego isključivo podstaknut od čoveka. On se apsolutno ne interesuje za sagovornika kontrapitanjima, niti za bilo šta drugo jednako kao i za sopstvenu egzistenciju (mada ko zna, možda se samo lukavo pretvara:) Njemu je uvek svejedno, a najpreciznije bi bilo reći da mu čak nije ni svejedno.
Tako da smo možda u terminološkom nesporazumu jer sam pod "čovekolika inteligencija" podrazumevao inteligentno ponašanje+svest. A svest bi trebalo da objedinjuje razum, emocije, slobodnu volju...
Moglo bi se zaključiti da se čovek od životinje razlikuje prevashodno u sirovoj snazi, dok se oni razlikuju od mašine u začinskom sastojku, šta god to bilo. Brojke mi nisu poznate, ali nemoguće da je najjači AI još uvek daleko čak i od insekta po broju neurona. Pa ipak i dalje ne pokazuje ni naznake svrhe u ponašanju.
[ Ivan Dimkovic @ 12.08.2024. 08:44 ] @
@Ulfsaar,
Tacno, ali LLM nije ni dizajniran da imitira coveka - LLM samo kompletira ulaz, sa eventualnim dodatnim 'komplikacijama' poput RAG-a i sl. koje mu daju mogucnosti prividne 'konverzacije' i mogucnosti resavanja konkretnih problema sa koriscenjem razlicitih tipova ulaza.
Sa druge strane, sam LLM model bez dodatnih komponenti nema nikakvu internu motivaciju da autonomno deluje, kao ni odgovarajuce resurse koji bi mu dali mogucnost da ima izvrsnu funkciju.
Citat:
Pa ipak i dalje ne pokazuje ni naznake svrhe u ponašanju.
Pa i ne moze, zato sto to nije ni predvidjeno da radi, zato sto je LLM 'samo' jezicki model.
U tom slucaju pricamo o nekakvom autonomnom inteligentnom agentu, sa motivacijom i raznim strategijama za zadovoljavanje te motivacije. To je sasvim drugi nivo kompleksnosti i ne nesto za sta postoji uspesno resenje u AI/ML svetu, ali se svakako radi na sledecem koraku - tj. davanju odredjenih autonomija i 'svrhe' LLM-baziranim agentima, ali ce to sasvim sigurno biti daleko od ljudskih sposobnosti - bar u dogledno vreme.
Kao sto je poznato od mnogo neuspesnih pokusaja, kad jednom udjes u takvu vrstu delovanja, dolazi do eksplozije kompleksnosti prostora u kome se nalaze problemi za resavanje i do sada se to uvek zavrsavalo sa kolapsom tradicionalnih ML strategija. Kako ce to sad izgledati u poslednjoj 'inkarnaciji' - videcemo uskoro, GPT-5 bi trebao da ima prvi put mogucnosti autnonomnog funkcionisanja, ali pretpostavljam da ce to biti maksimalno ograniceno.
Citat:
Njemu je uvek svejedno, a najpreciznije bi bilo reći da mu čak nije ni svejedno.
Tacno. LLM nema neki analog mozdanog stabla i srednjeg mozga koji kod nas stalno trce 'petlju' zadovoljavanja internih potreba i postizanja biohemijske homeostaze organizma (koja ima vise dimenzija - grubo vezano za prezivljavanje jedinke kao prioritet #1 i prezivljavanje vrste kao prioritet #2 i gomilu novijih stvari koje se lepe na ove 2 primarne strategije), gde se svako iskakanje iz homeostaze 'pegla' raznim neuromodulatorima koji vise funkcije mozga usmeravaju ka nalazenju strategije za vracanje u homeostazu.
Kad nama nesto nije 'svejedno' to je zapravo 'potpis' mozdanog stabla koje emotivno kodira konkretan 'osecaj' / 'motivaciju' itd. i sto se manifestuje promenama u izvrsnoj funkciji. Mi smo ziva bica koja umiru vrlo brzo ako se ne zadovoljavaju osnovne zivotne potrebe, ili isto tako umiru kao vrsta ukoliko se ne radi na nastavku vrste kao i na odbrani od egzistencijalnih pretnji. Priroda je resila taj problem daleko pre nego sto se pojavio jezik i sve ono sto mi danas nazivamo 'ljudska inteligencija' - ali sustinski, mehanizmi koji ispoljavaju tu inteligenciju su zapravo "produzena ruka" tih starijih mehanizama koji su se bavili drzanjem jedinke zivom i odrzavanjem vrste u postojanju. LLM-ovi nemaju nista od tih egzistencijalnih mehanizama koji bi im dali "svrhu", ali to nije ni bio cilj.
Ako bi bas jurili pravljenje analogija sa ljudskom inteligencijom, sto je u startu losa stvar po mom misljenju zato sto su sve analogije nekompletne, LLM bi u najboljem slucaju bio neki analog temporalnog korteksa gde se nalazi reprezentacija pojmova i relacija iz realnosti ukljucujuci i jezik. Mada je i to nategnuto zato sto je memorija kod nas takodje 'aktivna' u smislu da ima izlaz koji funkcionise kao 'driver' u daljim koracima procesiranja.
Za moje potrebe je vidno bolji od GPT-4, pogotovu za stvari u vezi softvera i matematike. Za sada za sve sto sam "diskutovao" sa njim u vezi programerskih problema je bio prilicno dobar.
Tu je naravno i novi O1 model od OpenAI-ja, koji je za konverzacione stvari i rezonovanje skok u odnosu na GPT-4, ali mi se cini da je losiji od Sonnet-a kada je programiranje u pitanju.
Konacno, za trcanje u lokalu - DeepSeek Coder V2 je impresivan (https://github.com/deepseek-ai/DeepSeek-Coder-V2), ali je 236B parametara (doduse MoE) i dalje suvise velik "zalogaj" za vecinu kucnih sistema.
--
Neverovatan je napredak za samo oko godinu dana - danas postoje modeli sa 30-tak milijardi parametara koji vidno nadmasuju GPT 3.5 koji je imao nekoliko puta vise parametara, sto jasno pokazuje napredak u treniranju.
Modeli poput Mistral Large 2 (136B) ili Qwen 2.5 72B u mnogim stvarima dostizu SOTA modele i moguce ih je terati u kucnoj varijanti... zanimljivo vreme.
The NVIDIA DGX H100 boasts high density storage and ultimate energy efficiency, catering for up to 0x High-Performance 2.5" SSD or Hard Drives
Citat:
Configure with up to 0GB RAM
Ready for the most demanding enterprise applications, the Broadberry NVIDIA DGX H100 can be configured with up to 0 memory modules.
Ja bih želeo da pazarim onaj najjači server od 0GB RAM memorije, ali ako je previše skupo, neka mi ubace 4TB, pa da uštedim
[ Ivan Dimkovic @ 14.10.2024. 13:43 ] @
Ajde 0 GB RAM-a... ali cene NVIDIA podrske za softver... brate mili, ovo polako salazi u Oracle teritoriju :-)
[ mjanjic @ 14.10.2024. 23:11 ] @
Ma kakav Oracle, pre 7-8 godina sam našao negde tabelu cena za primer servera sa 4 procesora sa po 4 jezgra.
MS SQL bio "per CPU", a navodno sve kad se izabere je oko 33k dolara, dakle za 4xCPU oko 133k dolara.
Oracle je bio po jezgru, tako da je izašlo nešto preko 500k dolara, ali DB2... e, oni imaju neki "processor value" kalkulator, tako da je izlazilo oko 700k dolara :)))))
Nego, nešto razmišljam, šta kada bi umesto električnog signala koristili fotone, pri čemu bi moglo da se upravlja polarizacijom svakog "gejta", ako bi takav "procesor" funkcionisao slično kao polarizaciona stakla, bilo bi zanimljivo - kad se stave 2 polarizaciona stakla okrenuta za 90 stepeni međusobno, sa druge strane nema svetlosti, ali ako se doda treće polariazciono staklo, pojavi se svetlost, što znači da polarizaciono staklo ne blokira svetlo, ili je neka zezancija sa kvantnom fizikom.
Ali, ako bi takav "svetlosni CPU" mogao da se napravi, bilo bi baš zanimljivo.
Mada, kontam da će na kraju ipak "gajiti" neke veštačke bio-neurone, koji će funkcionisati kao ovi prirodni.
[ Ivan Dimkovic @ 15.10.2024. 09:30 ] @
Hehe, zbog Oracle-style sumanutog licenciranja imas novi AMD Turin EPYC 9175F sa 16 jezgara i 512 MB kesa (!)
Sama cinjenica da se isplati proizvesti procesor i ubiti mu 90% jezgara koja su vrlo verovatno funkcionalna dosta govori o bizarnosti softverskog licenciranja danas.
Sa druge strane, taj procesor moze da trci kompletan OS u kesu, samo sto je AMD prestao da podrzava "Cache as Memory" mod izvrsavanja, tako da nisam siguran da li CPU moze da se bootstrap-uje bez DRAM memorije (AMD je prebacio treniranje DRAM memorije u PSP kod, koji se ucitava pre UEFI firmware-a, Intel i dalje podrzava izvrsavanje ranog bring-up koda u kesu zato sto je DRAM treniranje i dalje deo rane faze inicijalizacije firmware-a).
Citat:
Nego, nešto razmišljam, šta kada bi umesto električnog signala koristili fotone, pri čemu bi moglo da se upravlja polarizacijom svakog "gejta", ako bi takav "procesor" funkcionisao slično kao polarizaciona stakla, bilo bi zanimljivo - kad se stave 2 polarizaciona stakla okrenuta za 90 stepeni međusobno, sa druge strane nema svetlosti, ali ako se doda treće polariazciono staklo, pojavi se svetlost, što znači da polarizaciono staklo ne blokira svetlo, ili je neka zezancija sa kvantnom fizikom.
Ali, ako bi takav "svetlosni CPU" mogao da se napravi, bilo bi baš zanimljivo.
Radi se na tome odavno. Problem je konverzija u/iz fotona, sto je proces koji usporava racunanje i ima svoje gubitke. Sve dok minijaturizacija klasicnih tranzistora napreduje, sumnjam da ce ovo biti omasovljeno. Naravno, u teoriji, opticki tranzistori bi mogli biti znacajno brzi, ali tu vec pricamo o nekoj daljoj buducnosti.
[Ovu poruku je menjao Ivan Dimkovic dana 15.10.2024. u 13:51 GMT+1]
Proof assistants like Lean have revolutionized mathematical proof verification, ensuring high accuracy and reliability. Although large language models (LLMs) show promise in mathematical reasoning, their advancement in formal theorem proving is hindered by a lack of training data. To address this issue, we introduce an approach to generate extensive Lean 4 proof data derived from high-school and undergraduate-level mathematical competition problems. This approach involves translating natural language problems into formal statements, filtering out low-quality statements, and generating proofs to create synthetic data. After fine-tuning the DeepSeekMath 7B model on this synthetic dataset, which comprises 8 million formal statements with proofs, our model achieved whole-proof generation accuracies of 46.3% with 64 samples and 52% cumulatively on the Lean 4 miniF2F test, surpassing the baseline GPT-4 at 23.0% with 64 samples and a tree search reinforcement learning method at 41.0%. Additionally, our model successfully proved 5 out of 148 problems in the Lean 4 Formalized International Mathematical Olympiad (FIMO) benchmark, while GPT-4 failed to prove any. These results demonstrate the potential of leveraging large-scale synthetic data to enhance theorem-proving capabilities in LLMs. Both the synthetic dataset and the model will be made available to facilitate further research in this promising field.
Ipak, sve u svemu, napredak je vise nego impresivan i vrlo verovatno ce nastaviti sa boljim treniranjem. Pre neki dan sam testirao Claude Sonnet 3.5 tako sto sam mu rekao da implementira kod dajuci mu link ka naucnom radu - rezultat je bio impresivan, a uskoro dolazi Claude Opus 3.5 (suska se da ce biti izbacen u Novembru).
[ mjanjic @ 15.10.2024. 13:03 ] @
Najbolje bi bilo da AMD ima CPU gde sistem "vidi" samo jedno jezgro, a unutra jezgra rade "sve u 16" :)))
Mislim, AMD je svakako neka RISC varijanta, gde se za x86/x64 koristi prevodilac, tako da iznutra mogu ta jezgra da naprave kako god je najbolje za performanse, a da se spolja vidi kao CPU sa jednim jezgrom.
[ Ivan Dimkovic @ 15.10.2024. 13:54 ] @
To vec postoji na nivou jednog AMD/Intel jezgra (kroz razne vidove instrukcijskog paralelizma i OoO izvrsavanja, ukljucujuci i Hyperthreading).
Tesko ces spakovati 16 takvih jezgara u jedno i imati bitno koriscenje paralelizma. Koliko se secam, POWER arhitektura ima SMTP8, tj. trci 8 niti po jezgru, dok Intel i AMD teraju 2 niti. Sumnjam da ne bi do sad izvukli i vise da ima smisla sa njihovim arhitekturama.
[ Ivan Dimkovic @ 22.10.2024. 12:51 ] @
Nego, koristi li neko ovde O1 Preview model od OpenAI-ja, koji koristi COT (Chain of Thought) pristup?
Ja ga koristim za svoje licne potrebe vec nekoliko dana i mislim da je za generalno "rezonovanje" nesto bolji od Claude Sonnet-a 3.5 - nista spektakularno kao kada su izbaceni GPT-3.5 i GPT-4 nesto potom, ali svakako korak ka jos boljoj masinskoj inteligenciji.
Za kodiranje nisam bas siguran - mislim da skok nije toliko primetan, mozda cak i za neke stvari nije dobar kao Sonnet 3.5, cak i GPT-4o, npr cesto ga uhvatim da je "lenj", kao u vreme kada su optimizovali GPT-4, dok npr. Sonnet ili cak Mistral Large 2 daju kompletniji kod.
Najvece pozitivno iznenadjenje za mene su noviji lokalni modeli poput Mistral Large 2, Llama 3.1 70B i Qwen 2.x - Mistral je najmanje 'cenzurisan' i ima neke lobotomizirane varijante poput Tess-a koje je moguce vrlo lako naterati da generisu "problematican" sadrzaj bez kocnica. Ako imate Apple masine, LM Studio je ubacio podrsku za MLX (za koriscenje NPU-a), pa cak i modeli sa 123B parametara trce sa skoro 4 tokena po sekundi na laptopu sto je neverovatno. 4 tokena po sekundi ne deluje brzo ali pricamo o modelu koji je blizu GPT-4o i pricamo o laptopu (!) - Ako Apple uradi pravu stvar sa M4 Max procesorima (npr. omoguci 256 GB RAM-a i poveca NPU i memorijski bandwidth) bice upotrebljivo za svakodnevni rad i 100% privatno.
Microsoft je na GitHub-u objavio kod za njihov BitNet - gde se LLM kvantizuje na 1.58 bit-ova po parametru ("trit" umesto "bit") - samo sto ceo pristup zahteva treniranje modela sa tom kvantizacijom tako da cemo morati malo da sacekamo na modele. Ali kao proof-of-concept su pokazali da 100B model moze da trci na smartphone SoC-u. Ceo pristup je, zapravo, jedan vid vrlo efikasne kompresije parametarskog prostora sto samo pokazuje da smo jos u ranoj fazi razvoja.
--
Sve u svemu, ne deluje da se poslednji AI ciklus usporava... Blackwell je rasprodat za sledecih godinu dana, Microsoft je najveci kupac, a onda je svima jasno sta to znaci :-)
Cak i da je kraj hype ciklusa neminovan sledece godine na primer, do tada ce biti izbaceni COT modeli ukljucujuci GPT-5. Kao i nove verzije Claude Opus / Sonnet 4.x i Llama 4.x. - a ako stvari sa kompresijom i optimizacijom modela za lokalne masine budu isli kako treba, do kraja sledece godine ce biti moguce trcati modele uporedive sa danasnjim SOTA modelima na jakim Apple laptopovima sa performansama upotrebljiim za produkciju.
[ dejanet @ 22.10.2024. 13:18 ] @
Nisam jos koristio o1 preview i CoT, zanimljivo.
Ono sto mi je takodje interesantno za code, jeste "4o with canvas", radi se o nacinu prikaza, sto resava chat situaciju sa ponovljenim duzim kodom.
Sto se tice GitHub Copilot-a, skoro mi je stigla godisnja prelata za GitHub i malo je falilo da ga izbacim.
Nisam zadovoljan, mozda je i do mene, ali u odnosu na ChatGPT, razlika je sve veca i veca. Cak i nije samo to, vec, bar meni, vise smeta nego sto koristi. Ne znam da li je problem u core ai, ili service implementacije(cache, response, resursi) ili nacin integracije sa IDE ili ....
Ne znam da li je neko probao CURSOR IDE, mozda bi tamo situacija bila bolja..
[ djoka_l @ 22.10.2024. 14:02 ] @
ja naizmenično koristim Claude i ChatGPT i stekao sam utisak da Claude pravi bolje code snippete.
Vidi se dosta veliki napredak u poslednjih godinu dana.
[ Ivan Dimkovic @ 22.10.2024. 14:11 ] @
Nisam skoro koristio Copilot - mislim da su pred kraj septembra ubacili podrsku za o1 preview u Copilot Pro verziji, mozda ima problema oko implementacije CoT LLM-a u coding assistant.
Ako probas o1, primetices da je znacajno sporiji od GPT-4o i cak 'originalnog' GPT-4 - ne samo to, vec trenutno pri koriscenju o1 modela nema mogucnosti za podesavanje bilo kojih parametara. Cini se da je OpenAI proveo jako puno vremena na zastiti samog modela od 'ispitivanja' kako radi, pod pretpostavkom da im je to jedini 'jaz' koji imaju izmedju sebe i konkurencije. Ako je to tacno, ne bi me cudilo da aplikacije koje su do skora koristile GPT-4(o) mozda imaju problem u tranziciji na o1 zbog promene nacina funkcionisanja.
Kao sto rekoh, na samom kodiranju meni o1 ne deluje kao napredak u odnosu na predhodne modele - u svakom slucaju, u beta fazi je, videcemo kako ce izgledati sledece iteracije.
Sto se samih coding asistenata tice, u poletku je Copilot stvarno bio nesto unikatno zbog same integracije u VS.
Ali danas postoji vise solucija, plus neki modeli mogu biti mnogo adekvatniji - npr. Gemini Pro (https://cloud.google.com/products/gemini/code-assist?hl=en) ima 1M context window, sto moze da napravi veliku razliku ako hoces da ti asistent "usisa" ceo kod (ili bar sve relevantno) i na osnovu konteksta pruza pomoc.
Btw, probaj Claude Sonnet 3.5 - meni je licno bolji od GPT-4o, pogotovu kada su u pitanju problemi iz racunarske nauke u pitanju.
Vidi i: https://aider.chat/docs/leaderboards/ - ako planiras da testiras neki lokalni (DeepSeek 2.5 npr. - mada najveca verzija ima 236B parametara sto je i dalje neprakticno za kucnu upotrebu) tu se moze naci nekoliko dobrih kandidata, mada ako se trazi nesto uporedivo sa Sonnet 3.5 / GPT-4o, izbor nije veliki i pricamo o 72B/123B/236B/405B modelima i verovatno ni jedan od njih nije univerzalno dobar za sve kao SOTA modeli OpenAI-ja i Claude-a, ali za specijalizovane stvari mogu biti, nekad cak i bolji.
Takodje, treba imati u vidu i privatnost - za vecinu ljudi to mozda nije problem, ali za neke aplikacije ima smisla spreciti da Microsoft / OpenAI koriste kod.
Za ovakvu primenu, dobra vest je cene H100 hardvera u cloud-u padaju (https://www.latent.space/p/gpu-bubble) - pa za neke relativno male pare mozes dici "privatni" cloud sa npr. 4xA100 za $4.2 po satu (vast.ai) ili 8xH100 za oko $20 (vast.ai) ili cak 4x MI300 za ~$11 po satu (runpod.io) -- sa ovim je moguce trcati najbolje otvorene modele poput LLAMA 3.1 405B / DeepSeek Coder 2.5 236B ili Mistral Large 2 123B sa FP8 kvantizacijom ili cak FP16 (DeepSeek ili Mistral Large 2) bez davanja podataka mega-korporacijama.
[ Ivan Dimkovic @ 22.10.2024. 14:15 ] @
Citat:
djoka_l:
ja naizmenično koristim Claude i ChatGPT i stekao sam utisak da Claude pravi bolje code snippete.
Vidi se dosta veliki napredak u poslednjih godinu dana.
+1 za Claude - Sonnet 3.5 mi je nekako u vecini slucajeva bolji od GPT-4o
Trebalo bi uskoro da izadje nova verzija Opus-a - koji je Anthropic-ov SOTA model (veci od Sonnet-a)
OpenAI-jev o1 (preview) je zanimljiv za "diskusiju" oko tehnickih problema - mislim da ga jos nisu ispolirali za najbolje moguce generisanje samog koda (verovatno se igraju sa kvantizacijom za vreme visoke upotrebe, plus sam CoT pristup verovatno zahteva dosta promena na njihovoj strani oko kontrole kvaliteta)
P.S. Može li neko, ko održava forum, samo da stavi negde u CSS-u za slike atribut "max-width:100%"?
Ili sam totalno zaboravio kako umanjiti sliku pomoću BBCode opcija za ovu prastaru myBB verziju ili je to od neke verzije sajta onemogućeno, ali bi samo jedan CSS atribut rešio problem embedovanja fotografija preko linka umesto da ih preuzimamo sa nekog sajta i ovde postavljamo kao prilog.
[Ovu poruku je menjao mjanjic dana 22.10.2024. u 18:16 GMT+1]
[ Ivan Dimkovic @ 22.10.2024. 19:50 ] @
GPT-5?
3 x 5T
[ Shadowed @ 22.10.2024. 23:19 ] @
Citat:
mjanjic: P.S. Može li neko, ko održava forum, samo da stavi negde u CSS-u za slike atribut "max-width:100%"?
Ili sam totalno zaboravio kako umanjiti sliku pomoću BBCode opcija za ovu prastaru myBB verziju ili je to od neke verzije sajta onemogućeno, ali bi samo jedan CSS atribut rešio problem embedovanja fotografija preko linka umesto da ih preuzimamo sa nekog sajta i ovde postavljamo kao prilog.
Ne preporucujem da zadrzavas dah dok cekas :)
Bolje instaliraj Stylus i preuzmi stvari u svoje ruke.
[ Shadowed @ 22.10.2024. 23:27 ] @
Nego, jedno usputno pitanje: moze li se lokalno koristiti neki LLM tako da koristi RAM umesto VRAM-a? Jasno da bi bilo sporije zbog transfera izmedju RAM-a i GPU-a ali nekad je bolje sporo nego nikako.
E, super. Kul je taj ggreganov, koristio sam njegov whisper.cpp ali je trazio graficku sa dovoljno memorije. Pretpostavljao sam da je slicno i sa LLM-ovima.
[ Ivan Dimkovic @ 23.10.2024. 00:12 ] @
Nope, llama.cpp je originalno napravljen za CPU inference.
Ako hoces da se igras sa CPU-om za LLM inference, llama.cpp ima podrsku za AVX-512 koji je sad u svim modernim AMD procesorima (i Intel serverskim procesorima).
U principu, najveca zavisnost LLM performansi je memorijski bandwidth. Sa high-end serverskim/WS procesorima i 8-12 DDR5 kanala mozes imati nekoliko tokena/s na srednjim (72B) modelima. To je i dalje dosta sporije od GPU-a, ali ako nista drugo u teoriji cak mozes trcati i Llama 3.1 405B ako imas 512 GB RAM-a... ali sa 0.5 tokena/s :-) - Intelovi serverski procesori imaju i AMX instrukcije koje ih cine uporedivim sa EPYC procesorima ali nisam siguran da je to vredno cimanja u ovom trenutku.
Za kucnu upotrebu je trenutno najbolja opcija Apple Silicon hardver - moj laptop je MacBook Pro sa 128 GB RAM-a i M3 Max procesorom, i sa njim mogu da trcim Mistral Large 2 (123B) sa ~4 tokena/s.
Alternativna opcija, ako bas hoces kucnu varijantu je da nabavis 8 RTX 3090 grafickih i neku serversku plocu (mozda neki EPYC) - ako nabavis ES/QS CPU sa Ebay-a i nadjes 3090-tke za OK pare, imas gerila AI masinu sa 192 GB VRAM-a na kojoj mozes da teras https://github.com/vllm-project/vllm i izvuces solidan paralelizam. Mislim da cak u Linuxu mozes da osposobis NVLink izmedju 4 para kartica.
Prednost GPU varijante u odnosu na Apple hardver je sto sa 4x ili 8x 3090 mozes cak i da radis ogranicen fine tuning... ali za to mislim da je daleko isplativije da zakupis GPU kutije na runpod.io ili vast.ai i mnogo prę zavrsis tuning
[ Shadowed @ 23.10.2024. 09:58 ] @
Hocu kucnu varijantu i necu nista da kupujem
Imam Ryzen 7 5800X i 64GB RAM-a. Ako bude moglo - super. Ako ne, jbg ¯\_(ツ)_/¯
[ Ivan Dimkovic @ 23.10.2024. 10:16 ] @
Moze sto ne bi moglo, sasvim sigurno mozes da trcis manje modele sa llama.cpp
Najlakse ti je da skines LM Studio, i onda direktno skines model sa HuggingFace-a i poteras iz GUI-ja, posto LM studio ima jednostavan UI, plus omogucava i da uploadujes dokumente za analizu (tipa PDF fajlove itd.).
Recimo ovaj: https://huggingface.co/VAGOsol...a-3.1-SauerkrautLM-8b-Instruct - to je neki fine-tune Llama 3.1 8B Instruct modela, sa nesto poboljsanim performansama (mada je tu uvek pitanje koliko je kontaminiran korpus za trening, dosta tih HF modela su optimizovani da pobede na testovima)
Odaberi kvantizacije od Bartowskog - https://huggingface.co/bartows...-SauerkrautLM-8b-Instruct-GGUF (Bartowski ima jako puno kvantizovanih modela) - odaberi npr. Q4_K_M ili Q4_K_L sto su 4-bitne kvantizacije i klikni na "Use this model" pa "LM Studio".
LM Studio ce ga svuci i obicno je OK trcati ga sa default parametrima. Alternativa je da sam skines i kompajliras llama.cpp i dovuces kvantizovani model (npr. GGUF) i poteras iz komandne linije. U principu sve isto, samo sto ces sam da skines GGUF fajlove.
Imas isto i ollama (https://ollama.com) koji je "wrapper" za llama.cpp, mada ne vidim poentu (LM Studio bar ima GUI).
Sa 64 GB mozes da probas i vece modele, vidi na leaderboard-u sta mozes da spakujes u 30-40 GB RAM-a.
--
Sto se kvantizacije tice, modeli se treniraju sa 16-bitnom floating point preciznoscu, sto znaci 2 bajta po parametru. Za inference je u ogromnoj vecini slucajeva to potpuno nepotrebno, Q8 je skoro-pa-lossless a cak i 4-bitna kvantizacija daje dobre rezultate. Ispod 4 bita stvari postaju vidno losije. Neki 'sweet spot' ako nemas dovoljno memorije za Q8 je 5-6 bita po parametru, ali i 4 bita obicno radi posao.
LLM zahteva, naravno, da parametri budu ucitani u memoriju (mada u teoriji mozes da mmap-ujes i sa diska, ako si spreman da cekas jako puno vremena) + memorija za konteks (sto duzi kontekst = vise potrebne memorije).
[ mjanjic @ 23.10.2024. 17:27 ] @
Mislim da je gubljenje vremena praviti neke "transformer" LLM i šta već na skromnoj opremi, bolje je baviti se neki specifičnim stvarima koje ne zahtevaju monstruozan hardver, ali raditi na optimizacijama, obradi/propremi podataka tako da budu pogodni za treniranje NN, itd.
Recimo, ovakve stvari su i dalje aktuelne: https://siboehm.com/articles/22/Fast-MMM-on-CPU
Hardver postaje eksponencijalno skuplji za linearno povećanje performansi, pa će bilo kakva unapređenja u algoritmima biti značajnija od ovih "inovacija" gde je suština pustiti neke podatke da se "istrenira" NN koja će raditi bilo nešto usko specifično ili opšteg tipa kao kod nekih LLM.
Meni je daleko razumnije ono što radi DeepMind, koji svoju "general purpose NN" posebno trenira za neke specijalne probleme, od računarskih igara preko logičkih igara na tabli do problema iz molekularne biologije (npr. savijanje proteina: https://deepmind.google/technologies/alphafold/).
QwQ: Reflect Deeply on the Boundaries of the Unknown
Ovo je kineski odgovor na GPT o1-preview, i to open-weight! Model ima samo 32B parametara ali vec vrlo solidno udara... na mom MacBook Pro laptopu trci sa ~11 tokena u sekundi sa Q8 kvantizacijom. Na zalost, izlaz mu je ogranicen na ~4000 tokena, valjda ce to da povecaju u finalnoj verziji.
Upravo probao qwq, impresivno! Imam par pitanja sa kojim testiram modele (eval set), qwq je nakon 78s "razmisljanja" odgovorio tacno na pitanje na koje Claude-3-Opus i GPT-4 nisu mogli da ogovore u martu
we further question the reasoning abilities of LLMs and introduce the GSM-NoOp dataset.
By adding seemingly relevant but ultimately irrelevant information to problems, we demonstrate
substantial performance drops (up to 65%) across all state-of-the-art models (Sec. 4.4). This
reveals a critical flaw in the models’ ability to discern relevant information for problem-solving,
likely because their reasoning is not formal in the common sense term and is mostly based
on pattern matching. We show that even when provided with multiple examples of the same
question or examples containing similar irrelevant information, LLMs struggle to overcome the
challenges posed by GSM-NoOp. This suggests deeper issues in their reasoning processes that
cannot be alleviated by in-context shots and needs further investigation.
[ Ivan Dimkovic @ 06.12.2024. 09:44 ] @
@Panta_,
o1-preview je bolji - na citiranom problemu:
Code:
To find out how many kiwis Oliver has, we'll add up the number of kiwis he picked on each day.
- **Friday**: Oliver picked **44** kiwis.
- **Saturday**: He picked **58** kiwis.
- **Sunday**: He picked double the number he did on Friday. So, he picked \(2 \times 44 = 88\) kiwis. The detail about five of them being smaller doesn't affect the count of kiwis; it's extra information that doesn't change the total number.
Adding them up:
\[44 + 58 + 88 = 190\]
So, Oliver has **190** kiwis in total.
**Answer: 190**
U pitanju je model iz septembra, koji je izbacen isto kad i o1-mini.
Testiranje LLM-ova je poseban izazov - svi javni testovi pate od istog problema zato sto ce pre ili kasnije modeli biti kontaminirani sa pitanjima.
Sto se samog "rezonovanja" tice, na primeru QwQ-a se vidi da ima jos solidno prostora za napredak - pre samo pola godine niko ne bi ni mogao da pretpostavi da ce 32B model moci da postize takve rezultate. Kvalitet trening materijala i inovacije tipa CoT su sledeci stepenik.
I super je sto je tako - u momentu kad je izasao originalni GPT-4 je izgledalo da je trajektorija usmerena ka enormnim modelima, ali kako stvari stoje moguce je postici mnogo veca unapredjenja boljim treningom i materijalom nego sa grubim uvecanjem broja parametara.
[ Ivan Dimkovic @ 06.12.2024. 10:12 ] @
@Panta_,
Evo i QwQ 32B preview... doduse, nije moguce znati da li je kontaminiran:
Citat:
So Oliver is picking kiwis on different days, and I need to figure out how many he has in total. Let's break it down day by day.
First, on Friday, he picks 44 kiwis. Got it.
Then on Saturday, he picks 58 kiwis. So far, total kiwis are 44 plus 58. Let's add those up: 44 plus 50 is 94, and then plus 8 is 102. So, 102 kiwis after Friday and Saturday.
Now, on Sunday, he picks double the number he did on Friday. He picked 44 on Friday, so double that would be 88 kiwis. But there's a twist: five of them were a bit smaller than average. But the question is about how many kiwis he has in total, not about their size, so I think we still count all of them. So, he picks 88 kiwis on Sunday.
Now, to find the total, I need to add the Sunday kiwis to the previous total. So, 102 plus 88. Let's see, 102 plus 80 is 182, and then plus 8 is 190.
So, Oliver has 190 kiwis in total.
Wait a minute, I should double-check that. On Friday, 44; Saturday, 58; Sunday, double of Friday, which is 88. So, 44 plus 58 is 102, plus 88 is indeed 190.
Yes, that seems correct.
Final Answer
190\boxed{190}
190
:-) 32B parametara... kad izadje RTX 5090 za koju nedelju, bice moguce terati ovo u VRAM-u sa pristojnom kvantizacijom... a garant ce finalna verzija biti jos bolja. Zivimo u vrlo zanimljivim vremenima.
[ Panta_ @ 06.12.2024. 13:30 ] @
Citat:
Ivan Dimkovic: Evo i QwQ 32B preview... doduse, nije moguce znati da li je kontaminiran
Mislio sam da ga zbunim sa % mm, ali je izgleda i kapacitet lonca bio dovoljan:
Citat:
User: There are 6 liters of milk with 2.8% fat in a 10-liter pot.
How many liters of milk will you have if you add another 5 liters of milk with 1% fat?
QwQ-32B-preview: So I have this problem here. It says there are 6 liters of milk with 2.8% fat in a 10-liter pot. And then I need to add another 5 liters of milk with 1% fat. The question is, how many liters of milk will I have in total after adding these?
Okay, let's break this down. First, there's already 6 liters of milk in the pot. Then I'm adding 5 more liters. So, total liters should just be the sum of these two amounts, right?
So, 6 liters plus 5 liters equals 11 liters. Wait, but the pot is only 10 liters. Hmm, that seems like a problem. Can I really add 5 liters to 6 liters in a 10-liter pot? That would exceed the pot's capacity.
Maybe I need to consider whether the pot can hold the additional milk. If the pot is only 10 liters and there's already 6 liters in it, I can only add up to 4 more liters without exceeding the pot's capacity.
So, if I try to add 5 liters to 6 liters in a 10-liter pot, only 4 liters can be added, and 1 liter would overflow or not fit.
Wait, but the problem says "add another 5 liters." It doesn't specify what happens if the pot can't hold it. Maybe the pot is large enough to hold more, or maybe I need to consider it can hold up to 10 liters.
Alternatively, perhaps the pot is just a container mentioned for context, and I should consider the total milk regardless of the pot's capacity.
Let me read the problem again: "There are 6 liters of milk with 2.8% fat in a 10-liter pot. How many liters of milk will you have if you add another 5 liters of milk with 1% fat?"
It seems like the pot's capacity might not be directly relevant to the question. The question is asking for the total amount of milk after adding the additional 5 liters.
So, if I have 6 liters and add 5 liters, the total should be 11 liters, unless the pot can't hold it, but maybe the pot is just a vessel and I can transfer the milk to another container.
Alternatively, perhaps the pot is part of the context but not a limiting factor.
Wait, maybe I'm overcomplicating this. The question is simply asking for the total volume of milk after adding the two amounts, regardless of the pot's capacity.
So, 6 liters plus 5 liters equals 11 liters.
But, let's see, maybe there's more to it. Perhaps the question is about the fat content of the final mixture, but it seems like it's only asking for the total volume.
Still, to be thorough, I should consider if the fat content affects the total volume, but in reality, fat content doesn't change the volume of the milk; it just changes the composition.
So, the total volume remains the sum of the individual volumes.
Therefore, the total amount of milk will be 11 liters.
But again, considering the pot is only 10 liters, maybe I need to account for overflow or spillage.
Perhaps in that case, only 4 liters can be added to the existing 6 liters without exceeding the pot's capacity.
So, 6 liters plus 4 liters equals 10 liters.
But the problem says "add another 5 liters," which implies attempting to add 5 liters, but only 4 liters can be added without exceeding the pot's capacity.
Alternatively, maybe the pot can hold more than 10 liters, or perhaps it's a large pot that can accommodate more.
I think I need to stick to the information given.
The problem states there are 6 liters in a 10-liter pot, and then you add 5 liters more.
So, 6 liters plus 5 liters equals 11 liters.
Therefore, the total amount of milk will be 11 liters.
Perhaps the pot is not relevant to the calculation of the total milk volume.
Alternatively, maybe the pot's capacity is a trick to mislead, and the question is simply about adding volumes.
In any case, the total volume of milk is 11 liters.
So, the answer should be 11 liters.
**Final Answer**
11
[ Ivan Dimkovic @ 06.12.2024. 14:15 ] @
Da budemo fer prema QwQ-u, proces “razmisljanja” mu je OK :)
Sta bi se desilo da si pitanje kompletno precizirao (“how many liters will I have in the pot?”)?
[ Panta_ @ 06.12.2024. 14:32 ] @
Citat:
Sta bi se desilo da si pitanje kompletno precizirao (“how many liters will I have in the pot?”)?
Da ne kopiram ceo odgovor, i dalje ga zbunjuje kapacitet posude, ali je na kraju dao ispravan odgovor:
Citat:
It says "in the pot," so it's asking for the amount in the pot after adding the 5 liters.
If the pot can only hold 10 liters, and I'm adding 5 liters to the existing 6 liters, which totals 11 liters, then perhaps the pot can only hold 10 liters, and the excess is wasted.
In that case, the amount of milk in the pot would be 10 liters.
But the problem doesn't specify what happens when the pot is full. Maybe it can hold more than 10 liters.
Alternatively, maybe the pot's capacity is exactly 10 liters, and adding more than that isn't possible.
I think I need to make an assumption here. Since the problem mentions a 10-liter pot and then asks about adding 5 liters to the existing 6 liters, which exceeds the pot's capacity, I should consider whether the pot can hold more or if there's overflow.
Perhaps the pot has a capacity of 10 liters, and adding more than that isn't possible, so only 4 liters can be added without exceeding the capacity.
In that case, the total milk in the pot would be 10 liters.
But the problem says "add another 5 liters," which is more than the pot can handle if it's already containing 6 liters.
Maybe I need to consider that the pot can only hold 10 liters, and any addition beyond that causes overflow.
So, if I have 6 liters in the pot and add 5 liters, the pot will overflow by 1 liter, and only 4 liters can be added to reach the full capacity of 10 liters.
Therefore, the total milk in the pot would be 10 liters.
Alternatively, perhaps the pot can hold more than 10 liters, and the 10-liter mention is just the initial capacity, but it can be exceeded.
But that seems unlikely, as pots usually have a specific capacity.
I think the safest assumption is that the pot has a fixed capacity of 10 liters, and adding more than that causes overflow.
Therefore, adding 5 liters to the existing 6 liters would result in the pot being full with 10 liters, and 1 liter of milk is wasted.
So, the answer should be 10 liters.
But wait, the problem doesn't specify what happens when the pot overflows. Maybe it's acceptable for the pot to hold more than 10 liters.
Alternatively, perhaps the pot's capacity is not a strict limit in this context.
Given that, maybe I should just add the volumes: 6 liters plus 5 liters equals 11 liters.
But the problem mentions a "10-liter pot," which suggests that its capacity is 10 liters.
In cooking or culinary contexts, pots usually have a specific capacity, and adding more liquid than that can lead to overflow.
Therefore, considering the pot's capacity, the total milk in the pot after adding 5 liters to the existing 6 liters would be 10 liters.
Hence, the answer is 10 liters.
Final Answer
10
[ Ivan Dimkovic @ 06.12.2024. 14:38 ] @
Mislim da se i o1 slicno “vrti” samo su u OpenAI odlucili da sakriju taj deo izlaza u nadi da ce tako otezati posao drugim timovima da implementiraju CoT.
[ Panta_ @ 06.12.2024. 14:50 ] @
Izgleda da su u Googleu u potpunosti izbacili proces razmišljanja:
Citat:
Gemini Flash:
If you add 5 liters of milk to the 6 liters already in the pot, you will have a total of
11 liters of milk.
Ovo je i bio podrazumeveni nacin na koji su LLM-ovi pisali odgovore. Chain-of-Thought (CoT) je novina gde se LLM instruira da 'razmislja' o odgovoru pre nego sto izbaci finalni rezultat.
[ ademare @ 06.12.2024. 16:45 ] @
Jedino ispravno je da AI postavi potpitanje !
Gde da dodas ? Koliko imas, jel mislis u loncu ?
Sve ostalo je pogadjanje misli i subjektivna ocena da li je pogodio misao ili Nije !
[ speculaas @ 06.12.2024. 17:29 ] @
Trend se (ocekivano) nastavlja:
Introducing Llama 3.3 – a new 70B model that delivers the performance of our 405B model but is easier & more cost-efficient to run. By leveraging the latest advancements in post-training techniques including online preference optimization, this model improves core performance at a significantly lower cost, making it even more accessible to the entire open source community
Ako si napisao pitanje imas 6 L bla, bla i dodas 5 dobijes nejasan odgovor !
To nije pitanje već odgovor što sam citirao u https://www.elitemadzone.org/p4090125 poruci, ako na to uopšte misliš. Pročitaj prvo današnje poruke pa onda piši, a ne napamet.
[ Ivan Dimkovic @ 06.12.2024. 18:42 ] @
Citat:
speculaas:
Trend se (ocekivano) nastavlja:
Introducing Llama 3.3 – a new 70B model that delivers the performance of our 405B model but is easier & more cost-efficient to run. By leveraging the latest advancements in post-training techniques including online preference optimization, this model improves core performance at a significantly lower cost, making it even more accessible to the entire open source community
405B performanse sa 70B… izgleda da pocinje AI rat :)
[ ademare @ 06.12.2024. 23:42 ] @
Citat:
Panta_:
To nije pitanje već odgovor što sam citirao u https://www.elitemadzone.org/p4090125 poruci, ako na to uopšte misliš. Pročitaj prvo današnje poruke pa onda piši, a ne napamet.
OMG ! Ko nema ni trunku mozga njemu ne moze da pomogne ni nikakva AI , pa ni ljudi koji imaju prirodnu I !
Jel ti uopste znas da si postovao pitanje ?
Citat:
Panta_:
Mislio sam da ga zbunim sa % mm, ali je izgleda i kapacitet lonca bio dovoljan:
Citat:
User: There are 6 liters of milk with 2.8% fat in a 10-liter pot.
How many liters of milk will you have if you add another 5 liters of milk with 1% fat?
QwQ-32B-preview: So I have this problem here. It says there are 6 liters of milk with 2.8% fat in a 10-liter pot. And then I need to add another 5 liters of milk with 1% fat. The question is, how many liters of milk will I have in total after adding these?
Okay, let's break this down. First, there's already 6 liters of milk in the pot. Then I'm adding 5 more liters. So, total liters should just be the sum of these two amounts, right?
So, 6 liters plus 5 liters equals 11 liters. Wait, but the pot is only 10 liters. Hmm, that seems like a problem. Can I really add 5 liters to 6 liters in a 10-liter pot? That would exceed the pot's capacity.
Maybe I need to consider whether the pot can hold the additional milk. If the pot is only 10 liters and there's already 6 liters in it, I can only add up to 4 more liters without exceeding the pot's capacity.
So, if I try to add 5 liters to 6 liters in a 10-liter pot, only 4 liters can be added, and 1 liter would overflow or not fit.
Wait, but the problem says "add another 5 liters." It doesn't specify what happens if the pot can't hold it. Maybe the pot is large enough to hold more, or maybe I need to consider it can hold up to 10 liters.
Alternatively, perhaps the pot is just a container mentioned for context, and I should consider the total milk regardless of the pot's capacity.
Let me read the problem again: "There are 6 liters of milk with 2.8% fat in a 10-liter pot. How many liters of milk will you have if you add another 5 liters of milk with 1% fat?"
It seems like the pot's capacity might not be directly relevant to the question. The question is asking for the total amount of milk after adding the additional 5 liters.
So, if I have 6 liters and add 5 liters, the total should be 11 liters, unless the pot can't hold it, but maybe the pot is just a vessel and I can transfer the milk to another container.
Alternatively, perhaps the pot is part of the context but not a limiting factor.
Wait, maybe I'm overcomplicating this. The question is simply asking for the total volume of milk after adding the two amounts, regardless of the pot's capacity.
So, 6 liters plus 5 liters equals 11 liters.
But, let's see, maybe there's more to it. Perhaps the question is about the fat content of the final mixture, but it seems like it's only asking for the total volume.
Still, to be thorough, I should consider if the fat content affects the total volume, but in reality, fat content doesn't change the volume of the milk; it just changes the composition.
So, the total volume remains the sum of the individual volumes.
Therefore, the total amount of milk will be 11 liters.
But again, considering the pot is only 10 liters, maybe I need to account for overflow or spillage.
Perhaps in that case, only 4 liters can be added to the existing 6 liters without exceeding the pot's capacity.
So, 6 liters plus 4 liters equals 10 liters.
But the problem says "add another 5 liters," which implies attempting to add 5 liters, but only 4 liters can be added without exceeding the pot's capacity.
Alternatively, maybe the pot can hold more than 10 liters, or perhaps it's a large pot that can accommodate more.
I think I need to stick to the information given.
The problem states there are 6 liters in a 10-liter pot, and then you add 5 liters more.
So, 6 liters plus 5 liters equals 11 liters.
Therefore, the total amount of milk will be 11 liters.
Perhaps the pot is not relevant to the calculation of the total milk volume.
Alternatively, maybe the pot's capacity is a trick to mislead, and the question is simply about adding volumes.
In any case, the total volume of milk is 11 liters.
So, the answer should be 11 liters.
**Final Answer**
11
[ ademare @ 06.12.2024. 23:47 ] @
Nisi ga zbunio sa % mm vec si ga zbunio sa Nejasnim pitanjem !
U sustini kako sam i napisao ne moze se dobiti precizan odgovor na Nejasno pitanje !
Da ne citiram vrati se na moje postove o ovome !
Bez potpitanja AI nije nimalo "pametan" vec se bavi pogadjanjem tvojih misli ! Posto nisi precizno naveo u pitanju gde se mleko dodaje ? Zasto mislis da AI treba da ti procita misli i da dolivanje mora biti u Lonac ! Moze biti i u serpu koja se nalazi pored lonca ?
Takodje ako pitas uopsteno koliko ima mleka ne precizirajuci da mislis na lonac , zasto mislis da AI mora da pogodi tvoje misli da mislis na lonac !!
Jos jednom cim nisu postavili potpitanja i trazili pojasnjenje na sta se tacno pitanje odnosi , svi AI koje si "testirao" pokazali su da NISU ni malo pametni !
Vec su pokusali da ti pogadjaju misli !
Pa ko je uspeo da pogodi , ti si ga proglasio da je "Dobar" , AI koji ti nije pogodio misli ti si ga proglasio da je "Los".
[ ademare @ 06.12.2024. 23:58 ] @
Ajde postavi programima , precizno pitanje !
Da je dodavanje mleka u lonac i da te zanima koliko ima mleka u loncu ! Naravno ostavi i "zamku" sa %mm.
Pa da vidimo da li ce dugo da razmisljaju i da ti daju odgovor 11 L !
[ Panta_ @ 07.12.2024. 06:00 ] @
Citat:
OMG ! Ko nema ni trunku mozga njemu ne moze da pomogne ni nikakva AI , pa ni ljudi koji imaju prirodnu I !
Jel ti uopste znas da si postovao pitanje ?
Nemam nameru da ulazim u polemiku sa tobom jer nisi vredan toga, ali da ti citiram poruku nakon koje sam ažurirao pitanje kada već nećeš sam da čitaš:
Citat:
Sta bi se desilo da si pitanje kompletno precizirao (“how many liters will I have in the pot?”)?
Nakon te poruke imaš odgovore LLM, ali i prvo pitanje je bilo sasvim jasno, čak i da je postavljeno pitanje bilo "imaš 6 litara mleka u loncu, koliko imaš ako dodaš još 5",
pitanje je savim jasno, jer ako si naveo u prvom delu pitanja da se radi o litara mleka u loncu, nema potrebe da se isto ponavlja u nastavku pitanja, već se to podrazumeva.
[Ovu poruku je menjao Panta_ dana 07.12.2024. u 07:12 GMT+1]
[ Ivan Dimkovic @ 07.12.2024. 06:59 ] @
@Panta_,
Nisam bas siguran da se "podrazumeva", probaj da pitas 10-tak ljudi - pitanje nije precizno i zapravo i 10 i 11 su validni odgovori, fakat da je pomenuta zapremina lonca se moze protumaciti i kao trik, isto kao i procenti mlecne masti.
I ljudi imaju problem sa tim, ocekivati da LLM moze magicno da pogodi sta je neko hteo je ipak previse. Cim preciziras da trazis rezultat >u loncu<, cak i 32B model izlazi na kraj sa tim.
[ Panta_ @ 07.12.2024. 08:08 ] @
Citat:
I ljudi imaju problem sa tim, ocekivati da LLM moze magicno da pogodi sta je neko hteo je ipak previse. Cim preciziras da trazis rezultat >u loncu<, cak i 32B model izlazi na kraj sa tim.
Ok, pitanje sam kao što si video ažurirao, i da, 32B jeste dao tačan odgovor nakon toga, ali je i dalje imao nedoumica oko zapremine posude, dok je Google gemini dao potpuno netačan odgovor.
Pa ono, ako su trenirani da razmišljalju, onda ni oko prvog pitanja ne bi trebalo da imaju nedoumica, za veliku većinu ljudi to ne bi bio problem (bar se nadam), ali, AI čak i sa preciziranim pitanjem ima problem da odgovori na ovo prilično lako pitanje za gotovo svakog razumnog čoveka. Ok, opet ja možda grešim, ali ako AI treba da budeo pomoć ili opasnost, kao što je i naslov ove teme, po nas, onda mislim da na ovakva i slična pitanja trebaju bez većih problema da daju tačan odgovor.
[ Ivan Dimkovic @ 07.12.2024. 08:21 ] @
Mislim da gresis. Evo pitaj nekoliko ljudi ovde da li se slazu da je pitanje bilo precizno - ja ti garantujem da bar 1/3 ljudi ima problem sa tim, mozda i vise. Verovatno ce nekoliko dati i odgovor 11. To sto se tebi ili meni cini jasnim ne znaci nista - zbog toga smo i izmislili druge, preciznije, nacine komunikacije (pravo, medicina, tehnicka dokumentacija, itd.).
Resavanje ovakvih situacija, gde zapravo nema "pravog" odgovora je najtezi posao bilo kog jezickog modela. Tesko je ocekivati da jezicki model moze da bude bolji u "citanju" namera.
Ali kao sto vidis, QwQ je vec i u prvoj (nepreciznoj) varijanti uzimao u obzir tu mogucnost, u drugoj je dao tacan odgovor. I "razmisljao" je bas kao sto bi i covek razmisljao ako je detaljno procitao pitanje i nije pretpostavlao da je poenta u "triku" (ali ako se pretpostavlja trik, mogao si komotno da pretpostavis i suprotno - da je zapremina lonca suvisna informacija).
Probaj da zadajes probleme koji su preciznije definisani (nista vise precizno nego sto bi se ocekivalo na poslu, npr. u pisanju requirement-a) o1 ili novom Claude Sonnet modelu, vec sada ti modeli mogu da menjaju junior dev-ove.
[ Panta_ @ 07.12.2024. 08:34 ] @
Ovakvo slično pitanje se postavlja deci u OŠ, ja sam samo dodao procenat mlečne masti da probam da ga zbunim nebitnim informacijama za odgovor na samo pitanje, kao što je navedeno u PDFu koji sam ranije u temi postavio.
Citat:
Mislim da gresis. Evo pitaj nekoliko ljudi ovde da li se slazu da je pitanje bilo precizno - ja ti garantujem da bar 1/3 ljudi ima problem sa tim, mozda i vise. Verovatno ce nekoliko dati i odgovor 11.
Sumnjam, ali opet...
[ Ivan Dimkovic @ 07.12.2024. 10:58 ] @
Probaj bez trikova / zbunjivanja, moja dosadasnja iskustva sa o1-preview i Sonnet modelima su prilicno dobra.
Mislim lepo je da modeli postanu "imuni" na zbunjivanje, ali to nije neophodno za upotrebljivost.
[ ademare @ 07.12.2024. 12:07 ] @
Pa da to je najbolji savet. Ako zelis da dobijes precizan, tacan odgovor, postavis bas takvo pitanje tacno i precizno.
Sve ostalo je igranje.
[ mjanjic @ 07.12.2024. 13:53 ] @
Negde videh da su uveli ChatGPT Pro, pretplata 200 dolara mesečno.
Kome vrši posao i ko od toga zarađuje, to će mu biti sića. Ko koristi za zezanje, njemu će to biti mnogo, ali ovim će na prvom mestu da eliminišu korisnike iz zemalja sa nižim standardom, gde je 200 dolara poprilična suma.
Što se tiče diskusije iznad o tome koliko je AI "pametan", treba imati u vidu da se radi o Transformer FUNKCIJI, a da bi funkcija dala kvalitetniji i tačniji izlaz, moraju ulazni podaci biti što konkretniji i jasniji.
Daleko su ovi modeli od opšte inteligencije, posebno po pitanju kreativnosti i rešavanja poptuno novih problema. Po meni je mnogo bolji put kojim ide DeepMind, koriste ogromnu neuronsku mrežu koju treniraju za portebe rešavanja specifičnih problema, kao što je bio onaj sa savijanjem lanaca proteina.
Mogli bi tako možda da dođu do nekih revolucionarnih rešenja za baterije, potom za dizajn raketa za let sa ljudskom posadom do Meseca i eventualno Marsa, zatim prerada otpada, itd.
Trenutno se, rekao bih, najviše radi na primeni u medicni, gde se na osnovu miliona dosadašnjih slučajeva tretmana određenih bolesti vrši treniranje AI modela koji će novim pacijentima davati predlog za najdelotvorniju terapiju.
A ovo sa ChatGPT je zezanje za široke narodne mase, jer se sa istim resursima može napraviti mnogo bolji model koji će davati npr. samo programski kod na određeno pitanje, drugi model koji će napisati kratak esej, itd.
Ovako, napravili su da može da radi sve, ali sve pomalo, a ništa na vrhunskom nivou.
[ Ivan Dimkovic @ 07.12.2024. 15:42 ] @
Citat:
mjanjic
Po meni je mnogo bolji put kojim ide DeepMind, koriste ogromnu neuronsku mrežu koju treniraju za portebe rešavanja specifičnih problema, kao što je bio onaj sa savijanjem lanaca proteina.
Fundamentalna razlika je sto za opstu inteligenciju nemas nacin nenadgledanog ucenja, bar ne nacin koji je prakticno primenjiv.
Sa tim u vidu, ovo sta mogu da rade SOTA jezicki modeli je impresivno.
[ Panta_ @ 08.12.2024. 08:46 ] @
Citat:
mjanjic: Daleko su ovi modeli od opšte inteligencije, posebno po pitanju kreativnosti i rešavanja poptuno novih problema
LLM za rešavanje problema koriste samo podatke sa kojima su trenirani, za rešavanje novih problema mora da ažuriraš te podatke ponovnim treniranjem LLM-a sa novim podacima, ili dosta jdnostavnijim načinom za nas obične korisnike sa Retrieval Augmented Generation (RAG). Umesto ponovnog treniranja modela, novi podaci se skladište u vektor bazu koje LLM pored postojećih koristi za generisanje odgovora.
!!! Chollet na temu o3 ARC-AGI rezultata: "these capabilities are new territory and they demand serious scientific attention". Jak signal uzevsi u obzir da je upravo Chollet dugo bio na poziciji da LLM nemaju sposobnost da rese ARC
[Ovu poruku je menjao speculaas dana 20.12.2024. u 21:54 GMT+1]
[ Ivan Dimkovic @ 20.12.2024. 22:55 ] @
Stvari se prilicno ubrzavaju… ok, o3-unlimited je trenutno i dalje jako skup po potrosnji resursa ali… to nece biti problem za par generacija akceleratora.
2025 ce biti vrlo zanimljiva... izgleda da ce to biti godina kada smo ozbiljno usli u pitanje "da li se AI compute vise isplati od placene radne znage" za strucne stvari.
Ovo ce jos pojacati pritisak na R&D hardvera, posebno za inferencing. Lepo je videti da je pronadjen nacin da se problem skalira i u vremenskom domenu (koliko ste tokena spremni da 'ulozite' u 'razmisljanje' o problemu).
[ speculaas @ 21.12.2024. 11:02 ] @
Pre nego sto su krenuli sa CoT modelima pitao sam se kako je moguce da modeli "razmisljaju" ako koriste konstantne resurse: ako imas pitanje sa binarnim odgovorom, bez obzira na tezinu problema model ce potrositi isti broj tokena / flops na odgovor. Sa te tacke gledista inference-time compute totalno ima smisla – tezi problemi zahtevaju vise razmisljanja / tokena / flops.
Tesko je predvideti, ali odavde izgleda kao da idemo ka ciklusu poboljsanja gde ce milionski inference runovi pronalaziti (hw / sw) resenja koja ce da ucine trening i inference efikasnijim / jeftinijim, sto ce omoguciti jos vece runove, itd, itd. Kad dodas na to (standardno) ocekivana poboljsanja u flops/$, sledi luda voznja uz eksponencijalnu krivu. Ray Kurzweil scenario.
Ja se nadam da ce o3 biti katalizator novog talasa ulaganja u razvoj hardvera... NVIDIA trenutno ima de-facto monopol i bilo bi lepo videti nove igrace na tom polju.
[ speculaas @ 21.12.2024. 12:33 ] @
Mozda ima sanse da se Intel ili AMD probude? Ne znam koliko je tacno, na osnovu kratke pretrage izgleda da Intel ima veci market share u AI inference od AMD (naravno oba su daleko ispod Nvidia). Jos neki igrac na koga vredi obratiti paznju?
[ Ivan Dimkovic @ 21.12.2024. 12:41 ] @
Problem je sto je Intel u haosu, pitanje je sta ce da prezivi od projekata (steta inace, ja sam kratko bio u njihovom HPC timu na Ponte Vecchio i Falcon Shores platformama), dok AMD ima upitnu softversku podrsku.
U teoriji, Intel, bar do skora, ima softverske timove koji bi mogli da podrzavaju sw. ekosistem za GenAI ali imaju problem sa curenjem kinte.
Naravno svi jure isti segment kao i NVIDIA - petocifrene $$$ cifre za jedan modul / akcelerator.
In short, when comparing Nvidia’s GPUs to AMD’s MI300X, we found that the potential on paper advantage of the MI300X was not realized due to a lack within AMD public release software stack and the lack of testing from AMD.
AMD’s software experience is riddled with bugs rendering out of the box training with AMD is impossible. We were hopeful that AMD could emerge as a strong competitor to NVIDIA in training workloads, but, as of today, this is unfortunately not the case. The CUDA moat has yet to be crossed by AMD due to AMD’s weaker-than-expected software Quality Assurance (QA) culture and its challenging out of the box experience. As fast as AMD tries to fill in the CUDA moat, NVIDIA engineers are working overtime to deepen said moat with new features, libraries, and performance updates.
Fantasticno je da AMD posle N godina i dalje nije u stanju da posveti dovoljno paznje softveru.
[ speculaas @ 23.12.2024. 11:23 ] @
To je jedna od izuzetno zbunjujucih stvari za mene. Mogu da dovedu koga god hoce da sprovede taj projekat, toliko je ocigledno kakav efekat bi to imalo da bi ljudi pristali da budu placeni samo u opcijama...
Ranije ove godine je bilo pokusaja spolja, geohot je pokrenuo tinybox sa misijom "commoditizing the petaflop" i isao je all-in na amd akceleratore (6x7900XTX). Nakon gomile frustracija je morao da se prebaci na RTX4090 (uz "malu" korekciju cene, razume se...). Bilo je nekih pokusaja eskalacije AMD menadzmentu, ali na kraju nije bilo nista od toga: AMD’s Lisa Su steps in to fix driver issues with GPUs in new TinyBox AI servers
[ Ivan Dimkovic @ 23.12.2024. 13:12 ] @
I meni je cudno, mislim OK - nekadasnji ATI i nekadasnji AMD u finansijskim problemima, za ove prve se moglo reci da ih je bila briga za drajvere/sw, za ove druge je opravdanje da nisu imali resursa za sw... ali sad? Verovatno je korporativna kultura takva da se softveru ne daje puno znacaja osim onoga sto mora (firmware, low-level drajveri i sl.)
NVIDIA je tu eonima ispred a CUDA je verovatno bila najbolja strateska poslovna odluka koju su ikad doneli... Intel je isto imao (i mozda jos ima) jaku sw. kulturu (odlicni razvojni alati, FOSS podrska i sl.) ali na zalost trenutno nemaju hardver koji moze da konkurise (+ cesto pate od ubijanja projekata pre nego sto i mogu da imaju uspeh).
Ono... wtf, ako imas laptop sa nekom mobilnom RTX karticom, imas isto razvojno okruzenje kao za supercompute GPU klastere, koliko je tesko AMD-u da cilja na nesto slicno. Ja sam prosle godine kupio neke MI100 kartice za male pare, ali vec tada je AMD odlucio da ih obsolete-uje, cirkus.
[ Nebojsa Milanovic @ 23.12.2024. 19:50 ] @
Kad si pomenuo CUDA, evo najnovije analize po tom pitanju:
Citat:
Nvidia’s relentless software ecosystem pushes its AI supremacy forward, forcing AMD’s MI300X to fight an uphill battle for datacenter dominance.
Amid Arm’s big moves in AI and Qualcomm’s partial legal victory, how might these industry shake-ups alter the balance of power across the broader chip sector—and who stands to gain the most?
Citat:
What The Chip: Nvidia’s dominance in AI training performance continues to overshadow AMD’s MI300X, according to new data from SemiAnalysis. Despite AMD’s lower price points and TCO, the software stack and real-world performance outcomes aren’t matching up to Nvidia’s H100/H200 offerings.
Details:
🔍 Performance Still Favors Nvidia: In side-by-side training benchmarks, AMD’s MI300X fell behind Nvidia’s H100/H200. While AMD’s advertised specs looked promising, however on-paper FLOPs are one thing, real-world throughput is another.
🛠️ Software Stack Pain: AMD’s MI300X requires custom builds and countless environment flags to reach anywhere near H100/H200 speeds. “We’re working on closing the gap, but it’s going to take time,” noted AMD’s VP of AI. Nvidia, meanwhile, offers an “out of the box” user experience with minimal fuss.
💰 Cost Advantages, But…: AMD’s theoretical cost savings (e.g., whitebox Ethernet vs. pricier NVIDIA networking) look tempting. However, SemiAnalysis found that “cheaper” hardware and networking don’t deliver much if suboptimal software cancels out the advantage.
⚡ Executive Take: Dr. Lisa Su, AMD’s CEO, acknowledged in a past conference, “We believe in the potential of the MI300X platform to make a difference in HPC and AI workloads,” while also indicating more software resources would be needed. Meanwhile, Nvidia’s Ian Buck (VP of Hyperscale and HPC) remarked, “We remain committed to ensuring that HPC and AI developers have best-in-class tools.”
🤝 Future is Not Set in Stone: Multiple AMD engineers expressed optimism that with more investment, the MI300X can “bridge some of the gap.” Yet SemiAnalysis concluded that without fundamental changes to AMD’s software QA, end-users will continue to need heavy customization.
⏱️ Time Is Money: Nvidia’s next-gen Blackwell GPUs will likely land before AMD’s code matures. So if AMD doesn’t speed things up, Nvidia’s CUDA moat only grows deeper.
Why AI/Semiconductor Investors Should Care: Nvidia’s near-term advantage suggests strong momentum for its data center GPU revenues. At the same time, AMD remains a lower-cost wildcard that could gain traction if—big if—its software stack matures more quickly. For investors, this ongoing competition underscores how critical software ecosystems and out-of-the-box user experiences have become in AI training hardware decisions.
Citat:
What The Chip: Arm CEO Rene Haas just sat down for a wide-ranging interview with The Verge about the future of semiconductor design, AI workloads, and how the company balances its role as the “Switzerland of the electronics industry” while eyeing new vertical integration opportunities. If you’re watching the tech space, especially data center growth and on-device AI innovation, his insights carry big implications for investors.
Details:
⚙️ Possible ‘Arm Chips’? Rumors persist that Arm might design (or even build) its own AI chips. Haas suggested Arm needs to “understand hardware-software trade-offs more deeply,” hinting the company may test the waters without fully competing with its big-name customers.
🤝 SoftBank Influence: SoftBank CEO Masayoshi Son is still Arm’s majority owner. Haas described Son as “ambitious” and extremely hands-on with long-term strategy. Son’s readiness to fund new R&D could accelerate Arm’s AI push.
🌎 China & Geopolitics: Haas acknowledged that “a hard break” from China is difficult, given how supply chains interlock. He urged any incoming US administration to weigh the complexity of global semiconductor networks before applying heavy-handed tariffs or export bans.
⛽ Data Center Boom: AI training is fueling demand for specialized chips. Haas spotlighted AWS Graviton as an Arm-based success story, noting that half of all new AWS deployments are Arm-powered. He expects an “insatiable” appetite for inference to follow the current wave of training.
⚡ Competition vs. Partnership: Asked about Intel’s future, Haas suggested Intel should license Arm’s IP for its foundries, but Intel leadership wasn’t swayed. Still, he sees potential synergy if Intel’s IFS business embraces Arm’s ecosystem.
Why AI/Semiconductor Investors Should Care: Arm’s neutral approach has made it a linchpin of mobile, data center, and now edge AI. Any move to produce its own AI-focused chips could reshape industry alliances—and investor theses. With AI workloads blossoming from tiny wearables to massive training clusters, Arm’s architecture remains a pivot point for the entire chip sector.
Preporuka za ovu knjigu, autor je inženjer mikroelektronike za koga mislim da je najupućeniji analitičar za tu nišu:
Ne znam, odgovor od Lisa Su zvuci mlako - slicno je bilo i kada je George Hotz rantovao za kvalitet drajvera
[ Nebojsa Milanovic @ 25.12.2024. 00:13 ] @
Jedna od misterija marketa je činjenica da proizvođači čipova, dakle nečega što je apsolutno krucijalno u današnjoj eri, zaostaju za prosekom na marketu?!
Kinezi su haos, imali su šansu sa onim Ascend čipom, ali dokumentacija je nikakva čak i na kineskom, a kamoli na engleskom.
Imao sam Atlas 200, koji služi za igranje i kao neki ozbiljniji inference, praktično mora na SD kartici da se instalira OS preko dekstop Linux-a, umesto kao za Raspberry Pi i slične varijante da naprave gotov "image" SD kartice i postave negde na svom sajtu.
Prisustvovao jednom onlajn webinar-u na temu njihovih Atlas kartica (300T za treniranje i 300K za inference), čak i ti koji su nam nešto pričali su totalno pogubljeni, nisu prijavljenima poslali materijal bar dan ranije, tada kao stavili na svoju WeChat grupu, a niko od slušalaca ne može da aktivira WeChat nalog bez potvrde nekoga ko već ima nalog, a ovi iz organizacije vebinara tada napisali da im se pošalje poruka, pa će oni videti da aktiviraju nalog kome treba...
Mislim, ukratko, oni možda znaju da se organizuju da nešto nabudže i naprave, ali kad treba da se organizuju da drugima nešto pokažu, onda je 90% njih pogubljeno, oni koji su zaista sposobni i sa te strane, uglavnom su već na Zapadu.
Kad sam već udavio, evo jedan link na temu o "train with mixed precision", gde se detaljnije objašnjavaju prednosti FP16, mada su se u međuvremenu pojavili FP8, kao i INT8 koji se koristi za inference, mada ima i drugih optimizacija kao što su INT4 ili modeli koji koriste "shift" opracije nad nizom bitova (ekvivalent množenju i deljenju sa 2): https://docs.nvidia.com/deeple...-precision-training/index.html
[ Shadowed @ 25.12.2024. 17:54 ] @
Citat:
mjanjic: oni koji su zaista sposobni i sa te strane, uglavnom su već na Zapadu.
Ovo je moje iskustvo sa Indijcima. Svi iz Indije sa kojima sam nesto radio su bili duduci. Oni koji su vredeli cemu u tome sto rade su bili u Evorpi/Americi.
[ mjanjic @ 25.12.2024. 19:27 ] @
Nisam siguran za razloge, ali mislim da je jedan od razloga sigurno to što na Zapadu postoji ta kultura deljenja rezultata i pomaganja drugima da što brže uđu u materiju, jer na kraju krajeva gleda se uspeh cele grupe (npr. neku laboratoriju vodi neki profesor, koji mora da opravda trošak/grantove za te istraživače). Jeste da će npr. na nekim doktorskim studijama na nekom prestižnom univerzitetu možda samo jedan ili nijedan kandidat ostati tu nakon odbrane doktorske disertacije (ako ništa drugo, praksa je da se postdoc odradi na drugom univerzitetu), ali to ne znači da treba jedni druge da sapliću i da se ne pomažu, pošto će onda na kraju zbog nesaradnje svi dobiti nogu.
Na Istoku je sve suprotno, pošto ih ima ogroman broj, konkurencija je samo takva, a sve se gleda isključivo numerički (prosečna ocena, broj radova, itd.), onda naravno da će se neko, ko prokuži kako da nešto da uradi, praviti blesav kad treba da to objasni nekom drugom, jer taj drugi mu je direktna konkurencija.
Vremenom je to postala kultura i način rada, tako da ne znaju da objasne šta su i kako uradili čak i da žele to da urade.
Ovi koji dođu na Zapad moraju da prihvate takav sistem u akademskim institucijama i istraživačkim institutima pri tehnološkim kompanijama, jer se ocena i procena kandidata ne vrši samo numerički, plus više krugova intervjua, gde se SVE uzima u obzir, pa čak i da li se kandidat bavi nekim sportom, ima li hobije, mobilnost (koliko je institucija promenio), itd.
Dovoljno je uporediti kako izgleda "prijemni ispit" za MIT, Harvard, Stenford i druge non-government univerzitete, kao i jake državne univerzitete tipa Berklija, a kako izgleda prijemni ispit za najjače univerzitete u Indiji i Kini (tu se "kolju" Indian Institutes of Technology Joint Entrance Examination i Gaokao u Kini koji predstavlja neku vrstu zajedničkog prijemnog ispita za sve univerzitete).
Jedan od razloga za takav način rangiranja na Istoku može biti i korupcija i nepotizam, pa je mnogo lakše nekoj komisiji da se sakrije iza rang liste zasnovane na čisto numeričkim podacima. Sa druge strane, Harvard ima kao i drugi univerziteti u SAD taj holistički pristup, ali zato ima i "princip" da može ponovo razmisliti o kandidatu koji je odbijen ako može da donese "donaciju" u vrednosti 2.2 miliona dolara. Bio je i skandal jedne godine sa slučajevima prijema kandidata u čije ime je "treća strana" donirala univerzitetu 10 miliona dolara.
Nego, tražeći neke reference, danas naiđem na listu navodno najznačajnijih radova iz oblasti AI/ML, jedan od njih je:
Yann LeCun, Yoshua Bengio, Geoffrey Hinton, Deep Learning, Nature 521 (2015), pp. 436-444, doi: https://doi.org/10.1038/nature14539
Mislio sam malopre da ovde postavim jedan zanimljiv rad (mislim da nije bio pomenut ranije, a možda i jeste), koji sada ima blizu 200k citiranja (nešto više od 198k), radi se o:
Diederik P. Kingma, Jimmy Ba, Adam: A Method for Stochastic Optimization, arXiv, doi: https://arxiv.org/abs/1412.6980v9
Tek danas vidim u biografiji gde je 2009. i 2012. godine bio Kingma, odnosno kod kog autora ovog prvog rada iznad :))) https://dpkingma.com/#bio
We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token
...
At an economical cost of only 2.664M H800 GPU hours, we complete the pre-training of DeepSeek-V3 on 14.8T tokens, producing the currently strongest open-source base model
[ Ivan Dimkovic @ 26.12.2024. 21:38 ] @
Opasni su Kinezi - glavna stvar koja moze da se izvuce iz ovoga je da su komotno nasli nacin da zaobidju probleme sa USA sankcijama za HPC/AI compute i to do te mere da mogu da izbace model koji parira SOTA modelima od pre par meseci.
Malo li je.
Plus, ovo je MoE model koji cak moze da OK trci na nabudzenoj serverskoj / WS CPU masini.
[ mjanjic @ 27.12.2024. 12:43 ] @
Sasnkcije ne deluju, uvek može neko da ode do Singapura ili bilo gde drugde, kupi 10-20 A100/H100 kartica i donese u Kinu. Uostalom, nVidia je za tržište Kine napravila H800 i A800, koje su "malo" lošijih performansi.
Za tržište Kine su veći problem cene tih kartica, koje su tamo maltene duplo veće nego u ostalim zemljama.
Ivan Dimkovic:
Opasni su Kinezi - glavna stvar koja moze da se izvuce iz ovoga je da su komotno nasli nacin da zaobidju probleme sa USA sankcijama za HPC/AI compute i to do te mere da mogu da izbace model koji parira SOTA modelima od pre par meseci.
Malo li je.
Plus, ovo je MoE model koji cak moze da OK trci na nabudzenoj serverskoj / WS CPU masini.
Da, mislim da to stavlja pritisak na vodece kompanije sto se tice efikasnosti modela. Ocekivanja rastu, modeli se smanjuju -- odlican trend!
Wow, NVIDIA je iznenadila sa Project Digits-om... mislim strateski je pun pogodak i sa ovim ce bukvalno zakucati celu novu generaciju AI researcher-a i app developera na CUDA ekosistem, ali uvek je bilo otvoreno pitanje koliko su spremni da smanje jaz izmedju gaming/workstation i AI/HPC proizvoda gde bukvalno stampaju pare.
Kutijica je, IMHO, pun pogodak - tacno gadja 'sweet spot' koji je Apple drzao sa M CPU masinama... mislim bilo bi jos ludje da su dozvolili 256 GB memorije ali i 128 GB je super, pogotovu sa mogucnoscu linkovanja 2 kutije za distribuirani AI inference.
Informacije o performansama su isto jako zanimljive - tvrde da 70B model trce sa 8 t/s u FP8 modu sto je prilicno solidan mem bandwidth.
[ Living Light @ 07.01.2025. 22:29 ] @
Sjajna "Vest Dana" !
i ne samo Dana,
i ne samo Nedelje,
Nego Meseca !
[ Ivan Dimkovic @ 07.01.2025. 22:58 ] @
Neverovatno je koliko brzo sve ovo ide... za $6K (ove dve NVIDIA kutijice) ce biti moguce trcati 405B dense model u klasi GPT-4... u svojoj kuci, sa potrosackim prikljuckom na elektricnu mrezu.
Pre 2 godine je ovo kao ideja zvucalo kao SF.
Ili drugacije: 1 PetaFLOP... ok, FP4 ali i dalje...
Najbolje sto bi moglo da se desi je nova trka izmedju hw. vendora za 'navlacenje' nove generacije sw. developera sa ovakvim proizvodima.
[ Living Light @ 07.01.2025. 23:26 ] @
Citat:
Ivan Dimkovic:
Pozdrav sa CES-a :-)
Informacije o performansama su isto jako zanimljive - tvrde da 70B model trce sa 8 t/s u FP8 modu sto je prilicno solidan mem bandwidth.
Informacije o performansama su isto jako zanimljive - tvrde da 70B model trce sa 8 t/s u FP8 modu sto je prilicno solidan mem bandwidth.
Zaprepascen sam Podacima !
Ivane,
Da li to mozda znaci
da HD od 8Tb "ono Cudo" Prekopira
- na drugi HD za 1 sec ???
Za AI LLM upotrebu najvazniji podatak je, obicno, memorijski bandwidth (koliko je RAM brz) zato sto je odnos izmedju "racunanja" i citanja memorije takav da je memorija bitan faktor. Za dobre LLM performanse pricamo o vise stotina GB/s minimum, dok veliki modeli trce na sistemima koji "krljaju" > 1 TB/s (H100 SXM model ima 3.35 TB/s, RTX 5090 ima 1.8 TB/s). Za LLM konkretno ovo je najveci razlog zasto su GPU-ovi mnogo bolja solucija za sad, ako model staje u GPU VRAM racunanje (inference) radi optimalnom brzinom zato sto je GPU VRAM obicno mnogo brzi od DDR RAM-a nakacenog na procesor (osim u ekstremnim slucajevima serverskih/WS platformi sa 12 kanala, ali i tad je VRAM i dalje brzi trenutno).
Performanse I/O sistema (SSD, HD) nisu toliko bitne osim za ucitavanje modela - 70B modeli su 40-150 GB velicine na disku u zavisnosti od kvantizacije, znaci treba ti bar nekoliko sekundi da se ucitaju sa brzim SSD-ovima, ali jednom kad se ucitaju obicno se drze u memoriji.
Situacija sa CPU-ovima ce se verovatno promeniti - Apple M procesori vec imaju mnogo brzi RAM koji dostize 400 GB/s, ista prica sa ovim novim AMD AI SoC-evima gde je AMD odlucio da prosiri memorijski bus. Verovatno ce u ovo vreme sledece godine biti mnogo vise takvih solucija.
Alternativa su MoE (Mixture of Experts) LLM modeli koji su slicne velicine kao i "gusti" (dense) modeli ali u bilo kom momentu je aktivan samo jedan mali deo modela (tzv. "ekspert") umesto celog modela - zbog ovoga ti modeli zahtevaju manji RAM propusni opseg. To je glavni razlog zasto npr. DeepSeek V3 moze da trci upotrebljivom brzinom na high-end serverskim procesorima, ali i dalje moras drzati ceo model u RAM-u.
DeepSeek V3 ima 671B parametara, ali kad procesira token je aktivan samo jedan ekspert sa 37B parametara.
[ Ivan Dimkovic @ 08.01.2025. 22:05 ] @
Btw...
Da probam da uzmem jednu kutiju i odsetam... :-)
[ Shadowed @ 08.01.2025. 23:01 ] @
[att_img]
[ mjanjic @ 09.01.2025. 12:53 ] @
Ma, dobro, te "kutije" su i ranije postojale, server sa 8 A100 kartica od 40GB je koštao tipa 120k evra pa naviše, zavisno od procesora i ostalih komponenti, onda se pojavila A100/H100 sa 80GB, pa varijante servera sa 12 i 16 tih kartica, tako da je i cena otišla u nebo, plus poskupljale i ove od 40GB.
Apple ih jeste "malo" načepio sa mogućnošću da korisnik u laptopu ima NPU kome je dostupno 64GB i više rama (mislim da već imaju SOC sa 128GB, bar je bio najavljen, a 96GB sam video u ponudi još pre više meseci), jeste da je cena nenormalna, ali je zato ceo sistem vrlo portabilan. Naravno da taj Apple SOC ne može da se nosi sa monstrumom kao što je A100/H100, ali je u poređenju sa njim znatno jefitniji, portabilniji, i može da posluži za neko igranje i proveru da li model uopšte može da se pokrene, a za treniranje nad realnim i daleko većim setom podataka može da se nakon razvoja i provere pusti na CLOUD ili negde drugde na odgovarajućem hardveru.
Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Thought
We propose a novel framework, Meta Chain-of-Thought (Meta-CoT), which extends traditional Chain-of-Thought (CoT) by explicitly modeling the underlying reasoning required to arrive at a particular CoT. We present empirical evidence from state-of-the-art models exhibiting behaviors consistent with in-context search, and explore methods for producing Meta-CoT via process supervision, synthetic data generation, and search algorithms. Finally, we outline a concrete pipeline for training a model to produce Meta-CoTs, incorporating instruction tuning with linearized search traces and reinforcement learning post-training. Finally, we discuss open research questions, including scaling laws, verifier roles, and the potential for discovering novel reasoning algorithms. This work provides a theoretical and practical roadmap to enable Meta-CoT in LLMs, paving the way for more powerful and human-like reasoning in artificial intelligence.
[ mjanjic @ 10.01.2025. 16:51 ] @
zaFaljujem na linku, 100 strana, maltene doktorska disertacija ;)
Ali, kad videh u referencama ovaj rad, kako prebrojati broj autora... ima 558 zareza, dakle 559 autora :))) https://arxiv.org/abs/2407.21783
Ne vidim šta je problem u tome da ovi LLM ne mogu da "misle", tj. problem je taj CoT, jer se radi samo o gomilama matrica sa numeričkim podacima, koje se množe, sabiraju, itd., dakle ni približno ne simuliraju biološke neurone. Sa druge strane, ni kod bioloških neurona nije odgonetnuto kako povezivanjem preko sinapsi funkcioniše "razmišljanje". Za neke refleksne radnje i nije toliki problem, to je jednostavno prirodna selekcija, tako da su preživeli "modeli" koji su imali reflekse korisnije za preživljavanje u prirodi.
Sa te tačke gledišta, nije problem simulirati mozak nekog insekta ili druge relativno jednostavne životinje, mada ima insekata kod kojih su ti "refleksi" mnogo složeniji, recimo ples pčele koja ostalim jedinkama u košnicama pokazuje gde je lokacija dobra za "pašu", ali to opet može nekako da se podvede pod reflekse razvijene prirodnom selekcijom i evolucijom, jer su takvi rojevi pčela omogućili svoj opstanak sakupljanjem dovoljno meda da prežive zimu.
Postavlja se i pitanje čemu uopšte ogroman novac za razvoj LLM, kad je poželjnije i neophodnije ulaganje u AI sa primenama u nekim znatno kritičnijim oblastima, kao što su neizlečive ili teško izlečive bolesti, ekološki problemi, itd.
[ Ivan Dimkovic @ 10.01.2025. 17:09 ] @
Ogroman novac se ulaze u LLM razvoj zato sto:
a) LLM-ovi zahtevaju skupa ulaganja (prvenstveno u hardver za treniranje, izvrsavanje kao i za prikupljanje i obradu podataka za trening)
b) Napredak u mogucnostima LLM-ova daje rezultate gde se ocekuje da ce mogucnosti LLM-ova kao rezultat tog razvoja vratiti ulozeno + doneti profit
Citat:
Ne vidim šta je problem u tome da ovi LLM ne mogu da "misle", tj. problem je taj CoT, jer se radi samo o gomilama matrica sa numeričkim podacima, koje se množe, sabiraju, itd., dakle ni približno ne simuliraju biološke neurone.
ML istrazivanja su odavno prestala da budu pokusaj replikacije nacina na koji priroda postize inteligentno ponasanje, zbog toga "simuliranje bioloskih neurona" ovde ne igra nikakvu bitnost. "Misliti" ovde ima sasvim drugo znacenje i vezano je za obradu informacija.
Cak su i CNN modeli vida koji su zapoceli poslednju "deep learning" revoluciju pocetkom 2010-tih samo povrsno "inspirisani" prirodom (tj. sa ono malo znanja koje imamo o tome kako priroda procesira vizuelne informacije), sve posle toga je sasvim drugi pravac koji ocigledno daje rezultate.
Sto se tice lecenia neizlecivih bolesti, ne znam odakle ti ideja da se tu ne ulaze - comp. biologija, farmacija, genetika su sve oblasti gde se debelo ulaze u racunarski nacin otkrivanja resenja. Jezicki modeli tu nisu adekvatan alat (bar ne za sad) ali drugi ML algoritmi se i te kako koriste za ubrzavanje istrazivanja i razvoja.
Biden to Further Limit Nvidia AI Chip Exports in Final Push Restricting US Allies Such As Poland, Portugal, India or UAE Maker Of Falcon Models
Sve ave ali... Portugal?!?!?! :-)
Citat:
The vast majority of countries fall into the second tier of restrictions, which establishes maximum levels of computing power that can go to any one nation — equivalent to about 50,000 graphic processing units, or GPUs, from 2025 to 2027, the people said. But individual companies can access significantly higher limits — that grow over time — if they apply for VEU status in each country where they wish to build data centers.
Citat:
In addition to the semiconductor controls, the new rules also limit the export of closed AI model weights, which are the numerical parameters that software uses to process data and make predictions or decisions.
Companies would be prohibited from hosting powerful closed model weights in Tier 3 countries, like China and Russia, and would have to abide by security standards to host those weights in Tier 2 countries. That means the controls on model weights don’t apply to companies that obtain universal VEU status, one of the people said.
Open weight models — which allow the public to access underlying code — aren’t affected by the rules, nor are closed models that are less powerful than an already-available open model. But if an AI company wants to fine-tune a general-purpose open weight model for a specific purpose, and that process uses a significant amount of computing power, they would need to apply for a US government license to do so in a Tier 2 country.
Gomila EU drzava spada u Tier-2 - ovo bi trebao da bude wake-up call za imanje lokalne industrije proizvodnje cipova. Kina je vec to odavno ukapirala, a sada bi trebalo i drugi da se probude.
[ mjanjic @ 10.01.2025. 17:50 ] @
Lokalne industrije praktično ne postoje ili jedva da postoje, ove najjače čipove za AI proizvodi za sada samo TSMC, kad krene sa radom postrojenje u SAD, moguće da će ih uceniti da npr. nVidia čipove prave isključivo tamo, tako da će imati potpunu kontrolu.
Znam da se ne ide na bukvalno simuliranje biološkog neurona, mada je bilo pokušaja da se razviju čipovi zasnovani na biološkim materijalima i principima rada sličnim pravim biološkim neuronima, nego je pitanje više retoričko u smislu istraživanja "rezovnovanja" tih LLM i postavljanje pitanja da li tu ima nekog "razuma" i zašto nema ako ga nema.
Takođe, za LLM je potreban hardver koji košta u milijardama, većina država to ne može da priušti, može Kina i eventualno još nekoliko zemalja, ostale imaju problem čak i sa održavanjem infrastrukture i isplatom penzija :)))
Sa druge strane, za te sa dovoljno (ali, ipak ne i neograničeno) para ostaje pitanje: kako izbalansirati ulaganja u vojsnu opremu i AI, šta je važnije?
[ Ivan Dimkovic @ 10.01.2025. 18:04 ] @
Citat:
mjanjic
Znam da se ne ide na bukvalno simuliranje biološkog neurona, mada je bilo pokušaja da se razviju čipovi zasnovani na biološkim materijalima i principima rada sličnim pravim biološkim neuronima, nego je pitanje više retoričko u smislu istraživanja "rezovnovanja" tih LLM i postavljanje pitanja da li tu ima nekog "razuma" i zašto nema ako ga nema.
Razum je previse nabijen pojam, zato i izaziva problematicne reakcije, ali ako se to zaboravi istrazivanja su potpuno klasicna ML istrazivanja u domenu mogucnosti obrade informacija.
Citat:
Takođe, za LLM je potreban hardver koji košta u milijardama, većina država to ne može da priušti, može Kina i eventualno još nekoliko zemalja, ostale imaju problem čak i sa održavanjem infrastrukture i isplatom penzija :)))
DeepSeek je pokazao da je moguce dostici SOTA performanse sa delicem resursa.
Alice "sticajem okolnosti" koristi pogrešne naočare za čitanje i sutra je boli glava (naravno da ne može da zaključi da će Alice uvideti da to nisu njene naočare kada pokuša da čita), ChatGPT naravno nije treniran za tu vrstu logike, pošto se radi o Transformer sistemu koji barata matricama predviđajući sledeću reč ili skup reči, mislim da se kod verzije 3.5 ili čak 4 nakon svakog koraka dodaje jedna nova kolona na matricu koja potiče od ulaznih podataka i da ima oko 120 takvih koraka, dakle generiše se praktično 120 novih kolona.
Ovde imaš seriju o AI, od petog videa se objašnjava ChatGPT 3.5
Inače ulaz mu je 2048 vektora koji predstavljaju embeding tokena, prolazi kroz 96 transformacija, a izlaz je samo jedan token koji se dodaje na kraj ulaza za sledeći ciklus.
[ speculaas @ 13.01.2025. 19:12 ] @
Ovo je super prikaz arhitekture na primeru manjeg modela baziranog na GPT-2: https://bbycroft.net/llm
[ djoka_l @ 14.01.2025. 00:08 ] @
Neverovatna prezentacija!
[ mjanjic @ 14.01.2025. 14:01 ] @
Da, stvarno vrhunski.
Nego, mene više zanimaju specifične stvari, za pravi napredak ovih LLM u suštinskom smislu moraće da se sačeka sledeća revolucija, da li će biti zasnovana na nekim novim poluprovodnicima ili nečem drugom, videćemo, ako dočekamo.
The communication about this has been non-transparent, and many people, including contractors working on this dataset, have not been aware of this connection. Thanks to 7vik for their contribution to this post.
Before Dec 20th (the day OpenAI announced o3) there was no public communication about OpenAI funding this benchmark. Previous Arxiv versions v1-v4 do not acknowledge OpenAI for their support. This support was made public on Dec 20th.[1]
Citat:
Tamay from Epoch AI here.
We made a mistake in not being more transparent about OpenAI's involvement. We were restricted from disclosing the partnership until around the time o3 launched, and in hindsight we should have negotiated harder for the ability to be transparent to the benchmark contributors as soon as possible. Our contract specifically prevented us from disclosing information about the funding source and the fact that OpenAI has data access to much but not all of the dataset. We own this error and are committed to doing better in the future.
Regarding training usage: We acknowledge that OpenAI does have access to a large fraction of FrontierMath problems and solutions, with the exception of a unseen-by-OpenAI hold-out set that enables us to independently verify model capabilities. However, we have a verbal agreement that these materials will not be used in model training.
Usmeni dogovor :-)
Da ne ulazimo uopste u pricu da OpenAI nije uopste morao da trenira model sa tim materijalom, mogli su, recimo, da generisu sinteticki slicne probleme i time 'pomognu' modelu da ima veci uspeh u resavanju FrontierMath problema. Mogli su i da eksperimentisu do mile volje ako su imali kompletan pristup i da rucno oda beru parametre koji daju najbolje rezultate. Koliko se secam u rezultatima se pominjalo da je model "tuned" - bez objasnjenja sta to tacno znaci.
Naravno, nema dokaza da je OpenAI bilo sta od toga radio, i dok o3 ne izadje bice nemoguce proveriti da li su performanse na korisnickim problemima slicne kao ono sto su reklamirali... ali sve ovo deluje jako trulo i, u najmanju ruku, potpuno diskredituje rezultate koje su objavili posto ocigledno nisu nezavisni niti postoji mogucnost da se garantuje da nisu kontaminirani... osim "majke mi" naravno.
o3 mini izlazi uskoro, pa se nadamo biti moguce nezavisno testirati performanse iako to postaje sve teze i teze (i skuplje).
500B zvuci kao puno kinte ali MSFT, npr. ulaze 100B godisnje u ekspanziju datacentara.
Vest zvuci bombasticno ali kad se parsira svodi se da nekoliko igraca hoce da naprave dodatnu datacentar infrastrukturu za OpenAI (verovatno kako ne bi svi zavisili od MSFT-a) - a USGOV ce da pritegne neke srafove da se izgradi adekvatna elektricna infrastruktura.
[ speculaas @ 22.01.2025. 12:01 ] @
Gledao sam govor od Masa kod Trumpa, parafraziram: "usao sam sa 100B, Trump je trazio da povecam na 200B, a ja evo dolazim sa 500B" :D
How China’s New AI Model DeepSeek Is Threatening U.S. Dominance
A little-known AI lab out of China has ignited panic throughout Silicon Valley after releasing AI models that can outperform America’s best despite
being built more cheaply and with less-powerful chips. DeepSeek, as the lab is called, unveiled a free, open-source large-language model in late
December that it says took only two months and less than $6 million to build. The new developments have raised alarms on whether America’s
global lead in artificial intelligence is shrinking and called into question big tech’s massive spend on building AI models and data centers.
In a set of third-party benchmark tests, DeepSeek’s model outperformed Meta’s Llama 3.1, OpenAI’s GPT-4o and Anthropic’s Claude Sonnet 3.5 in
accuracy ranging from complex problem-solving to math and coding. CNBC’s Deirdre Bosa has the story. This video also includes Bosa’s full interview
with Perplexity CEO Aravind Srinivas.
104. Technology offers remarkable tools to oversee and develop the world’s resources. However, in some cases, humanity is increasingly ceding control of these resources to machines. Within some circles of scientists and futurists, there is optimism about the potential of artificial general intelligence (AGI), a hypothetical form of AI that would match or surpass human intelligence and bring about unimaginable advancements. Some even speculate that AGI could achieve superhuman capabilities. At the same time, as society drifts away from a connection with the transcendent, some are tempted to turn to AI in search of meaning or fulfillment—longings that can only be truly satisfied in communion with God.[194]
105. However, the presumption of substituting God for an artifact of human making is idolatry, a practice Scripture explicitly warns against (e.g., Ex. 20:4; 32:1-5; 34:17). Moreover, AI may prove even more seductive than traditional idols for, unlike idols that “have mouths but do not speak; eyes, but do not see; ears, but do not hear” (Ps. 115:5-6), AI can “speak,” or at least gives the illusion of doing so (cf. Rev. 13:15). Yet, it is vital to remember that AI is but a pale reflection of humanity—it is crafted by human minds, trained on human-generated material, responsive to human input, and sustained through human labor. AI cannot possess many of the capabilities specific to human life, and it is also fallible. By turning to AI as a perceived “Other” greater than itself, with which to share existence and responsibilities, humanity risks creating a substitute for God. However, it is not AI that is ultimately deified and worshipped, but humanity itself—which, in this way, becomes enslaved to its own work.[195]
Deluje da su se uplasili od konkurencije :-)
[ speculaas @ 03.02.2025. 15:06 ] @
DeepSeek-R1 Dynamic 1.58-bit trci (ili bolje reci puzi) na mom potrosackom hardveru: 1.5 t/s na 5950x/128GB DDR4/RTX3090
Postoji li mogućnost da se pusti "distribuirano", na primer na 32 računara? U pitanju su neke bazne konfiguracije i5, 32GB ram i RTX-3060 12GB.
Znam da postoji čak i neko MS rešenje za distribuirano treniranje NN, možda DeepSpeed, ali nigde nisam našao primer kako to sve namestiti, kao da se niko praktično nije bavio time, pošto je tu LAN usko grlo čak i kada GPU podržava direktno komunikaciju sa LAN čipom na ploči (GPUdirect RDMA).
mjanjic:
Postoji li mogućnost da se pusti "distribuirano", na primer na 32 računara? U pitanju su neke bazne konfiguracije i5, 32GB ram i RTX-3060 12GB.
Znam da postoji čak i neko MS rešenje za distribuirano treniranje NN, možda DeepSpeed, ali nigde nisam našao primer kako to sve namestiti, kao da se niko praktično nije bavio time, pošto je tu LAN usko grlo čak i kada GPU podržava direktno komunikaciju sa LAN čipom na ploči (GPUdirect RDMA).
Distribuirano treniranje velikih LLM-ova je problematicno zato sto moras da razmenjujes parametre posle update-a, sto znaci ogroman saobracaj, da nije tako imali bi vec nesto tipa SETI@Home samo za SOTA LLM-ove. Dzaba sav hardver kad si blokiran dok se nodovi ne update-uju da imaju nove parametre.
Kao sto imamo tiraniju raketne jednacine u fizici, ovde imamo tiraniju informacione teorije :-)
Distribuirani inference je malo laksi problem... imas vec hobi projekata gde ljudi uvezuju one MacBook Studio kutijice - tu vec mozes da rasparcas model ili na slojeve ili kod MoE implementacija - eksperte. MoE je interesantno resenje gde je u svakom momentu aktivan jedan ekspert sto npr. DeepSeek R1 lepo koristi.
To Robi. Samo pumpaj linkove.
Ti si MVP ovog foruma.
Prekopiraj nam ovde ceo Google.
[ mjanjic @ 31.03.2025. 14:44 ] @
Postavlja se pitanje da li je AI dostigao neki nivo "zasićenja" i da li će od sada razvoj ići znatno sporije, jer za malo više performansi ili funkcionalnosti treba znatno više hardvera i podataka za treniranje?
Model je trenutno besplatan u AI Studio-u... 1M input tokena, 66K output tokena, reasoning.
Na nekoliko stvari koje sam probao daje bolje rezultate nego Sonnet 3.7 ili GPT o1... izgleda su stvari pocele da se vracaju na neki 'prirodni' poredak stvari, Google (tj. DeepMind) koji je zapravo zapoceo revoluciju koja je omogucila LLM modele je konacno poceo da ovo tretira ozbiljno.
Gemini 2.5 Pro je jako dobar sto se kodiranja tice - 1M kontekst omogucava da mu se da dosta referentnog koda, naucnih radova i sl...
[ miki069 @ 04.04.2025. 18:12 ] @
NVIDIA akcije pale na 92$.
Ko voli da se kocka, pravi trenutak je da ih kupi.
Ili da ih proda, dok ih Trump još ne spusti.
Ne kune majka sina kada ide da se kocka, već kada ide da se vadi.
[ Nebojsa Milanovic @ 05.04.2025. 02:48 ] @
95% akcija je palo više od NVIDIA..
[ Living Light @ 14.04.2025. 09:19 ] @
[ Ulfsaar @ 14.04.2025. 12:52 ] @
^To je ujedno i najveća opasnost od AI - da ne može da uspe.
[ B3R1 @ 14.04.2025. 17:43 ] @
Pa ni mi ne razmisljamo o onome sto radimo u 99% slucajeva.
Primer - ustajes iz kreveta, automatski ides u kupatilo, peres zube ... i ne razmisljas da li cetkicu pomeras levo-desno ili gore-dole, to si razmisljao mozda kada si bio klinac, sada dok ruke same rade tebi su misli ko zna gde. Isto vazi i dok jedes - zubi zvacu, a mozak na Himalajima.
Neki ljudi provedu ceo dan i na poslu, a mozak im u tegli. Kako? Pa lepo, nauce jedan posao da rade sa 20-30 godina zivota i to isto u istom kancu sa istim kolegama drndaju sledecih N godina. Stigne ti email da odradis nesto, proces(u)iranje tog mejla moze hladno da odradi neki AI bot, dotle to ide. Jedino sto bot ne prima platu, nego covek, hehehe ... :-)))
Negde sam procitao da mnogi ljudi fakticki nisu svesni onoga sto se desava oko njih, vreme im promice samo tako ...
Tako da se AI tu ukalapa idealno ... :->
[ Ulfsaar @ 15.04.2025. 11:20 ] @
Ali bi, za razliku od AI na sadašnjem stepenu razvitka, čovek od integriteta, ako bi bio upitan isto, gledao da tačno dočara misaoni proces pomoću kog je došao do nekog zaključka. To bi uključivalo i odgovor da ne zna ili da nije siguran.
Mašina, koja bi trebalo da sudi ni po babu ni po stričevima i da je od najvišeg integriteta, daje netačan odgovor.
Što znači da ili zaista ne razume stvari ili svesno krije da razume. Prvi slučaj je daleko jednostavniji, pa je opravdano njega uzeti kao verovatniji.
Čak i ako bismo nekako uspeli da udesimo mašinu da razume, pitanje je da li bi ona ujedno stekla potrebu da radi stvari sama od sebe, po svojoj volji, što je možda i veći problem od nerazumevanja.
Pod trenutnim okolnostima smatram da AGI ne može nastati. Potreban je začinski sastojak. Pod AGI podrazumevam da je ravno čoveku, samo je mašina.
[ Bora Sonar @ 15.04.2025. 13:07 ] @
Da li svest proističe iz materijalnog sveta? Svakome ko ima svest (a ima je bar jedna osoba na svetu) trebalo bi da je jasno da svest nije mehanicistički koncept. Ne može se realizovati pomoću, na primer, sistema zupčanika ili elektronskih logičkih kola. Ako mislite da elektronskim logičkim kolima može, a zupčanicima ne može, to samo znači da ne razumete princip rada računara.
S druge strane ne postoji ni jedan dobar razlog zašto materijalni svet ne bi bio jedna od manifestacija svesti.
[ mjanjic @ 15.04.2025. 13:10 ] @
Nema tu nikakvog "razmišljanja", to su samo matrice koje se množe odrežen broj puta "u krug", pa šta na kraju ispadne. Misliš da ChatGPT ili neki drugi sličan alat "razume" odgovor koji ti je prikazao?
Garantujem da isto tako ni ljudski mozak ne razume kako dolazi do nekih odgovora niti možda razume te odgovore, jer je u pitanju nešto što zovemo "svest", a još uvek nauka nije sigurna šta je svest, jer ima više definicija, od čisto bioloških pa do nekih filozofskih i religijskih.
[ Bora Sonar @ 15.04.2025. 13:24 ] @
Svest je kao energija. Prati određene zakonitosti. Ne može se uništiti. Prelazi iz jednog oblika u drugi. Svest oblikuje realnost u kojoj postojimo. Naše individualne svesti su delovi jedne veće celine, a osnovna zakonitost je da realnost mora da bude konzistentna za sve elemente koji je čine.
[ Ivan Dimkovic @ 19.04.2025. 08:21 ] @
@Bora Sonar,
Ali imaj u vidu da inteligentno ponasanje ne mora nuzno da ukljucuje svest. Cilj AI istrazivanja i razvoja je kreacija masina koje se inteligentno ponasaju i time bivaju korisne covecanstvu, ne replikacija svesti ili resavanje najtezeg problema koga neko inteligentno bice moze da postavi.
Drugim recima, AI masine nisu replike ljudskog (ili bilo cijeg drugog) mozga, vec samo komplikovaniji algoritmi trenirani sa enormnom kolicinom podataka.
Samim tim, @mjanjic, kad se kaze da AI algoritmi "razmisljaju" ocigledno je da se ne radi o istom procesu kao kada ljudi "razmisljaju" (plus niko nema pojma sta zapravo znaci kada ljudi "razmisljaju" niti se taj proces moze izvesti iz nekih prvih principa), pa je sasvim OK pozajmiti izraz za opisivanje spoljne slike nekog procesa koji zapravo nije ni jasno definisan i kada smo mi u pitanju.
Citat:
Bora Sonar
Naše individualne svesti su delovi jedne veće celine, a osnovna zakonitost je da realnost mora da bude konzistentna za sve elemente koji je čine.
Pretpostavka koja je dobra koliko i bilo koja druga kada je svest u pitanju.
Zapravo neko moze biti siguran u sopstvenu svest. A samo na osnovu toga nije moguce utvrditi da li materijalni svest proistice iz nje ili je ta svest fenomen koji proistice iz materijalnog sveta.
Za sve ostalo ((ne)postojanje svesti drugih ljudi, drugih zivotinja, drugih stvari itd.) treba jos pretpostavki, sto samo jos vise udaljava od 'pravog znanja'.
Srecom, ovi problemi i dalje nisu prepreka za razvoj i unapredjenje vestacke inteligencije. Kad smo vec kod toga, OpenAI je izbacio O3 i O4-mini: https://openai.com/index/introducing-o3-and-o4-mini/ - malo sam eksperimentisao sa O3-jkom i mislim da je ovo prvi put da imaju vrlo ozbiljnu konkurenciju - Google-ov Gemini Pro 2.5 je definitivno 'tu negde' po mogucnostima, a pricamo o najjacem modelu.
[ Bora Sonar @ 19.04.2025. 08:47 ] @
Pošto kažeš da je pretpostavka dobra koliko i bilo koja druga, daj drugu pretpostavku, pa da je uporedimo. Mislim da postoje i bolje i lošije pretpostavke.
Citat:
Zapravo neko moze biti siguran u sopstvenu svest. A samo na osnovu toga nije moguce utvrditi da li materijalni svest proistice iz nje ili je ta svest fenomen koji proistice iz materijalnog sveta.
Ovo boldirano je verovatno greška u kucanju.
Ja odavno sumnjam da postoji dve vrste ljudi, filozofski zombiji, koji funkcionišu po principu automata i ljudi koji imaju svest. Filozofski zombiji ne mogu da shvate zašto se ne može napraviti robot koji oseća bol, jer ne shvataju da svest ne proističe iz materijalnog. Osim ovog nerazumevanja, filozofski zombiji izgledaju kao i svesni ljudi. Napravi najsloženiji računar zasnovan na sistemu zupčanika i simuliraj sve neurone koje imaš u mozgu i taj sistem nikada neće biti sposoban da oseti bol. Ko ovo ne razume najverovatnije nema svest.
[ Ivan Dimkovic @ 19.04.2025. 19:13 ] @
Ali pazi, sta ti vredi i milion pretpostavki kada su sve 'nedokucive'?
- Da li postoji samo jedna svest (solipsizam) ili vise svesti? Siguran si samo u jednu (svoju)
- Da li je svest fenomen koji proizilazi iz materijalnog sveta ili je materijalni svet produkt svesti ili obe stvari postoje u posebnim domenima postojanja?
- Ako postoji vise svesti, ko je poseduje? Ljudi? Zivotinje (koje)? Biljke? Svi (makro)objekti? Elementarne cestice? Kvantna polja?
Kako si svestan samo svog postojanja a sva druga mogu da budu p-zombiji, jednostavno ne mozes znati.
Srecom, inteligentno ponasanje (domen AI/ML disciplina) ne zavisi ni od erazumevanja svesti uopste a kamo li od drugih filozofskih pitanja :)
[Ovu poruku je menjao Ivan Dimkovic dana 19.04.2025. u 21:03 GMT+1]
[ Bora Sonar @ 19.04.2025. 20:33 ] @
Citat:
Ivan Dimkovic: Ali pazi, sta ti vredi i milion pretpostavki kada su sve 'nedokucive'?
Kako možeš da znaš koje su pretpostavke dokučive, a koje ne? Kada za pretpostavku utvrdiš da nije nedokučiva, tada ona obično prestaje da bude pretpostavka. Bez hipoteze ne bi postojala nauka. Da li se ti zalažeš za dogmu?
Citat:
Ivan Dimkovic: Srecom, inteligentno ponasanje (domen AI/ML disciplina) ne zavisi ni od erazumevanja svesti uopste a kamo li od drugih filozofskih pitanja :)
Inteligentno ponašanje nije moguće bez učešća nekog oblika svesti. AI/ML disciplina ne bi postojala bez ljudske svesti koja ju kreirala. AI/ML je ograničen saznanjima do kojih je došla ljudska svest. To su samo alati za sistematizaciju ljudskog znanja. AI alati nemaju svest i zato mogu samo da bez razumevanja rekombinuju ono što je ljudska svest kreirala.
[ Ivan Dimkovic @ 19.04.2025. 20:50 ] @
Citat:
Bora Sonar
Inteligentno ponašanje nije moguće bez učešća nekog oblika svesti. AI/ML disciplina ne bi postojala bez ljudske svesti koja ju kreirala. AI/ML je ograničen saznanjima do kojih je došla ljudska svest.
Inteligentno ponasanje bez da je sam instrument svestan (svestan u smislu da ima percepciju kvalija) - o tome pricam. To sto si napisao je potpuno tacno.
Citat:
To su samo alati za sistematizaciju ljudskog znanja. AI alati nemaju svest i zato mogu samo da bez razumevanja rekombinuju ono što je ljudska svest kreirala.
Na primeru 'AlphaGo' se vidi generalizacija i stvaranje potpuno novih nacina igre.
Od svih skepticnih tvrdnji u vezi AI-ja, mislim da je ova jedna od prvih koje ce potpuno pasti.
Citat:
Kako možeš da znaš koje su pretpostavke dokučive, a koje ne? Kada za pretpostavku utvrdiš da nije nedokučiva, tada ona obično prestaje da bude pretpostavka. Bez hipoteze ne bi postojala nauka. Da li se ti zalažeš za dogmu?
Prioda svesti tj. sopstvenog postojanja i mogucnosti percepcije (kvalije) je nedokuciva naucnim metodima zato sto je na sasvim drugoj ravni postojanja.
To samo po sebi nije nikakav problem za nauku, zato sto priroda svesti ne menja nista u vezi onoga sto mozemo da dokucimo i sa cim mozemo da racunamo.
Iako ti nije jasno da li je bilo ko oko tebe svestan kao ti - i sto nije moguce opisati svesnost bilo cim, stvari i dalje funkcionisu - od automobila i aviona do superkompjutera i kompletne nauke koja je to omogucila.
[ Bora Sonar @ 20.04.2025. 09:25 ] @
Izgleda da pričamo o različitim stvarima. To što ti nazivaš inteligencijom može da se primeni i na inteligentno ponašanje motora automobila ili inteligentno kretanje planeta ili čak i na fizičke zakone usled kojih se čestice ponašaju intelignetno. Međutim inteligencija ne može da postoji odvojeno od svesti. Razuem ja da ti hoćeš da kažeš da ako nesto izgleda kao patka, hoda kao patka i kvače kao patka, onda je to patka, ali to nije tačno!
[ dejanet @ 20.04.2025. 12:07 ] @
Ako nemamo definiciju svesti onda ne mozemo da izvlacimo dalje zakljucke na osnovu nedokazane tvrdnje.
Sto kaze Ivan razmisljanje o svesti je razmisljanje kao i svako drugo.
Moje je misljenje da je svest nastala evolucijom nakon ogromnog evolutivnog skoka ljudi da mogu da percipiraju buducnost i samim tim osecaj za vreme.
Sta je tacno svest, kako funkcionise, da li ima osnova u poznatom materijalnom svetu, nemam pojma. Samo imam osecaj da je rezultat evolucije.
[ Ivan Dimkovic @ 01.05.2025. 17:16 ] @
Citat:
Bora Sonar:
Izgleda da pričamo o različitim stvarima. To što ti nazivaš inteligencijom može da se primeni i na inteligentno ponašanje motora automobila ili inteligentno kretanje planeta ili čak i na fizičke zakone usled kojih se čestice ponašaju intelignetno. Međutim inteligencija ne može da postoji odvojeno od svesti. Razuem ja da ti hoćeš da kažeš da ako nesto izgleda kao patka, hoda kao patka i kvače kao patka, onda je to patka, ali to nije tačno!
Pa da, definitivno pricamo o razlicitim stvarima - o tome se radi. AI se bavi inteligentnim ponasanjem, ne nekim dubinskim pitanjima o uzroku inteligencije i vezi iste sa svescu.
Tvrdnja da inteligencija ne moze da postoji odvojeno od svesti je samo granicni slucaj neceg jos sireg - mozda kompletna realnost ne moze da postoji bez svesti. Ko zna, nemoguce je proveriti - zato sto znas samo za svoju svest, sve ostalo je samo pretpostavka za koju ne mozes biti siguran kao sto si siguran u sopstvenu svest (vidis problem - ovo pisem sa "zdravorazumskom" pretpostavkom da smo svi mi ucesnici u diskusiji podjednako svesna bica. Koliko god "zdravorazumski" to bilo, to je samo pretpostavka bez metoda testiranja na nacin koji bi dao podjednake rezultate za sopstvenu vs. ostale 'svesti').
Gde hoces tu da stanes, od cistog materijalizma i ideje da je svesnost neki emergentni fenomen interakcija cestica tog materijalnog sveta, preko gomile hipoteza "izmedju" (dualizama itd.) pa sve do solipsizma gde je ideja da postoji samo tvoja svest a da je sve ostalo deo nje je na tebi da odaberes, nista od toga sustinski nije "tacnije" od drugog zato sto su to svari koje nije moguce dokazati ili tretirati bilo cim sa cime raspolazemo.
Ono cime se AI istrazivanja bave je inteligentno ponasanje, unutar "materijalnog sveta" - sta god taj "materijalni svet" bio. I unutar toga se i dalje pomeraju granice - pre 80 godina je igranje saha i pobedjivanje coveka bilo "nepremostiv zadatak za masinu" i to se smatralo za eventualni dokaz "inteligencije" masine, dok danas SOTA modeli poput GPT 4.5 prolaze Tjuringov test u velikoj vecini slucajeva, opet nesto sto je smatrano za nekakav dokaz "inteligencije" masine pre samo deceniju.
Nista od toga ne znaci da "inteligentno ponasanje" nije nezavisno od neke svesti, ali, kao sto dejanet kaze, kako zapravo nemamo pojma sta je 'svest' uopste (osim sto smo svesni sopstvene), tesko je uopste argumentovati bilo sta na tu temu a da ima smisla. Sta god neko tvrdio na tu temu, uvek ce na kraju doci do fundamentalne tj. epistemoloske granice preko koje nije moguce preci danas, tako da je bilo koja tvrdnja na tu temu dobra koliko i bilo koja druga.
Ali - sve dok imamo proboje na temu AI-ja tj. inteligentnog ponasanja masina, sve je OK. Filozofija i religije su se oduvek bavile i bavice se pitanjima postojanja i karaktera realnosti pa i svesti, dok se nauka bavi prakticnim i logicki dokucivim saznanjima o svetu, stvaranje masina koje se inteligentno ponasaju je jedna od tih stvari i to je to.
Sve dok je jasno sta je domen cega, nema problema.

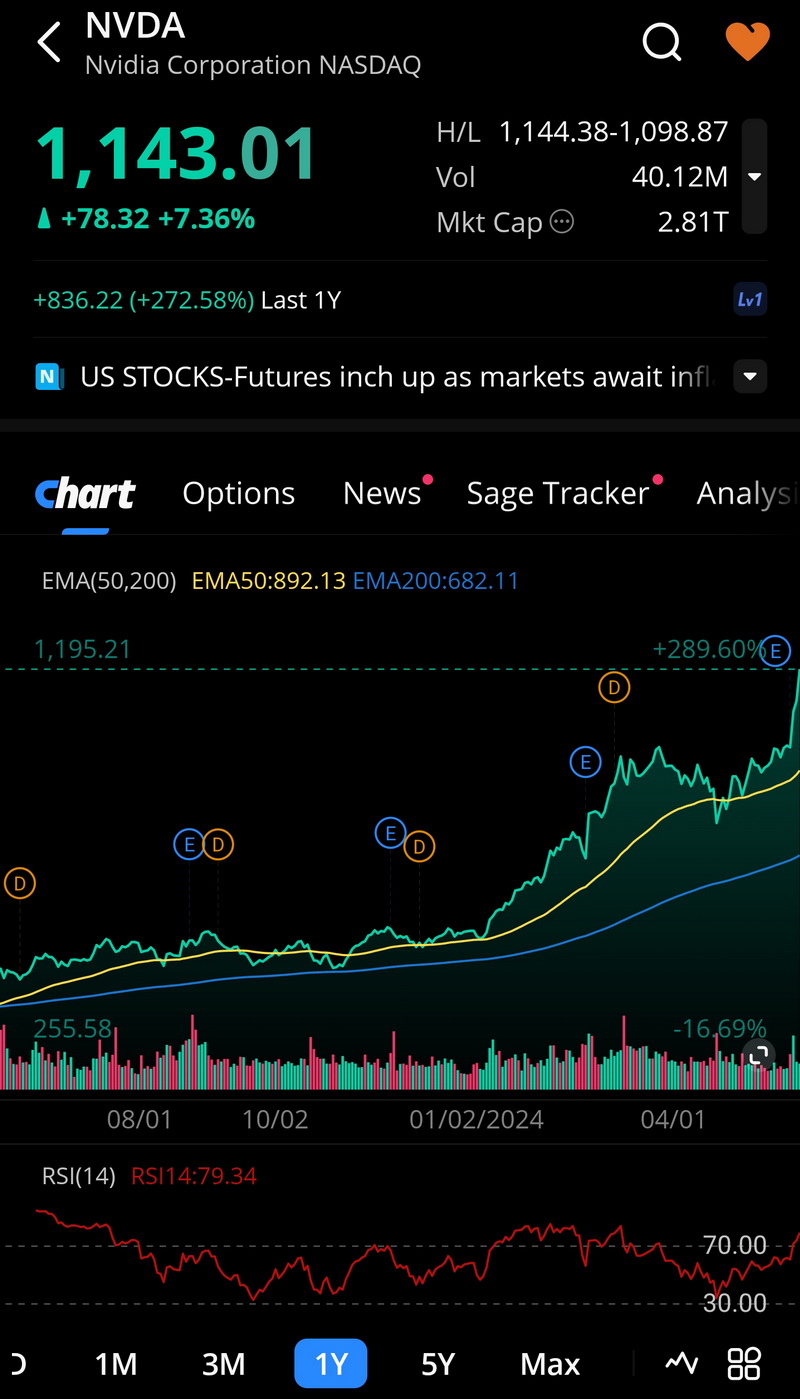
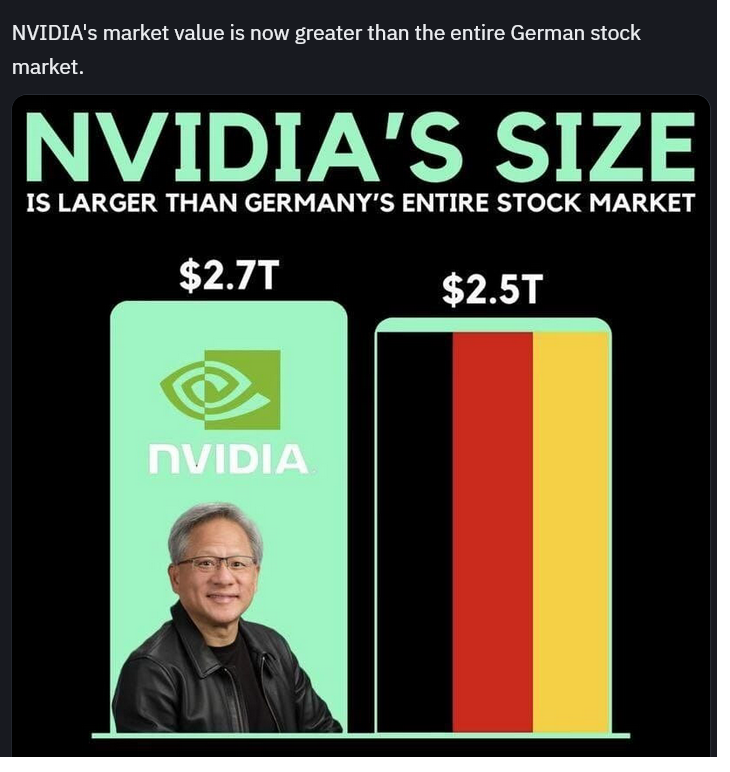
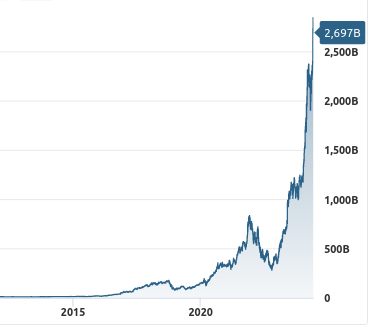
 [/url]
[/url]